
В отличие от предыдущей записи, здесь использованы практически все данные
по записям(в том числе приватным), комментариям и пользователям. Расширен
разрез данных и сделаны поправки. Для удобства, добавлены наглядные
графики.
Добавлено несколько объяснений как был получен данный результат.
*1.колличество пользователей 13989
*1.2.колличество пользователей написавших хотябы один пост 3372
*1.2.2 колличество пользователей написавших хотябы один пост или коммент 5445
*1.3 колличество всех записей 38777
*1.4 колличество всех комментариев 388484
*2.график пользователей по регистрации данных (по месяцам)
2.2 график тотал пользователей по месяцам
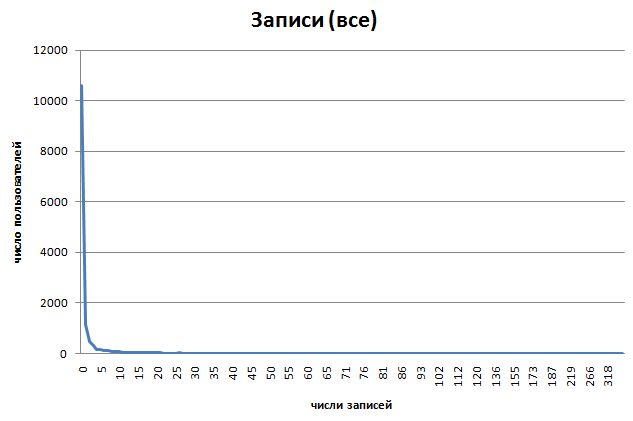
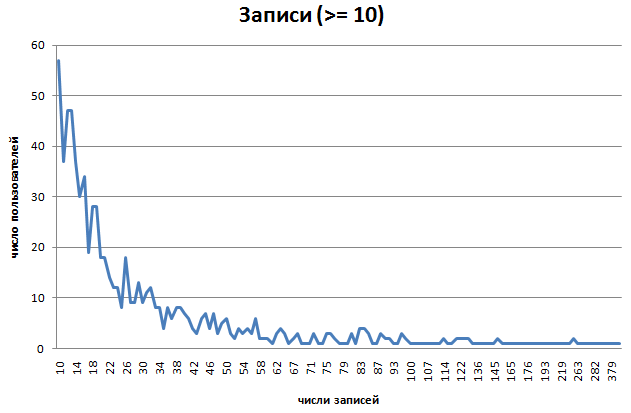
3.график пользователей по колличеству записей (log: 0, 1, 3, 10, 50, 100,
500, 1000)
3.2 первые 50 пользователей по записям
4.график пользователей по колличеству комментариев (Log: 0, 10, 100, 500,
1000, 5000, 10000)
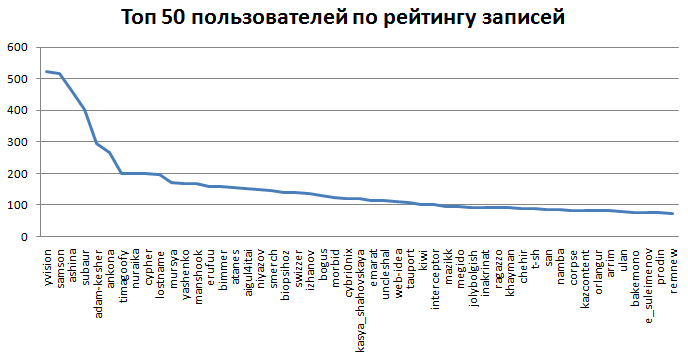
4.2 первые 50 пользователей по комментам
5.график рейтинга пользователей (-less, -10, -5, <0, 0, 5, 10, 50, 100,
300, 500, 1000)
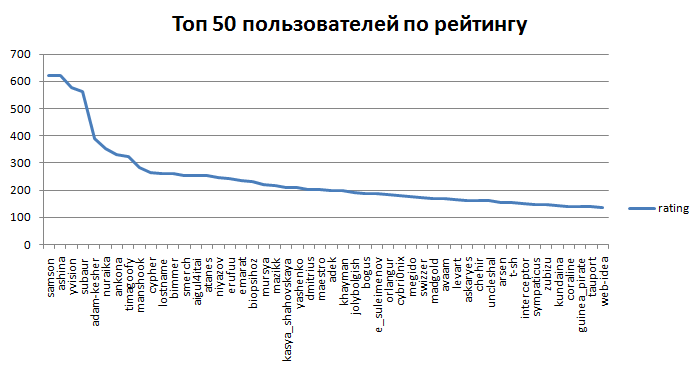
5.2 первые 50 пользователей по рейтингу
*7. 20% пользователей генерируют 98% и 60% сообщений соответственно
*8. 20% и 2% пользователей генерируют 99% и 73% комментариев соответсвенно
* 20% и 2% пользователей имеют 50051.39 и 28277.72 рейтинга соответственно при общем балансе 46593.38 рейтинга по всей платформе и при сумме всего позитивного рейтинга 50278.51
Как были получены данные:
-источник: веб страницы yvision.kz. Вся использованная информация доступна каждому пользователю сети интернет.
-инструменты: 80 строк Python кода для извлечения и фильтрации данных,
Excel для анализа и графиков.
Что хотелось бы добавить:
-анализ звязей между пользователями
-динамику изменения рейтинга для каждого пользователя втечении времени
-что ещё? есть идеи? делитесь!
В отличие от предыдущей записи, здесь использованы практически все данные по записям (в том числе приватным), комментариям и пользователям. Расширен разрез данных и сделаны поправки. Для удобства, добавлены графики. Добавлено несколько объяснений как был получен данный результат.
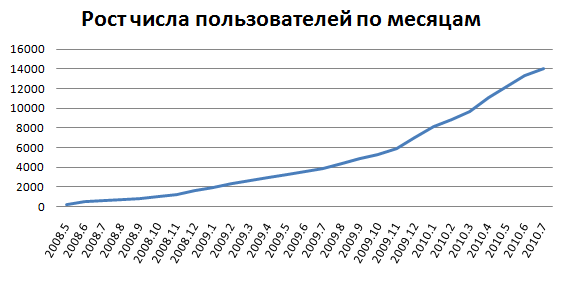
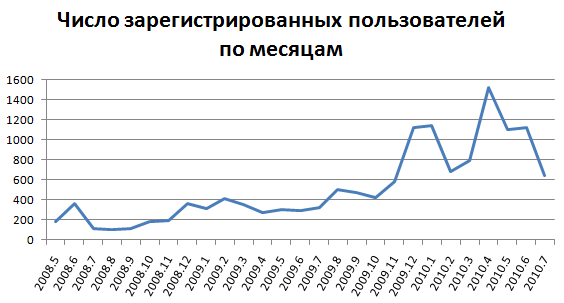
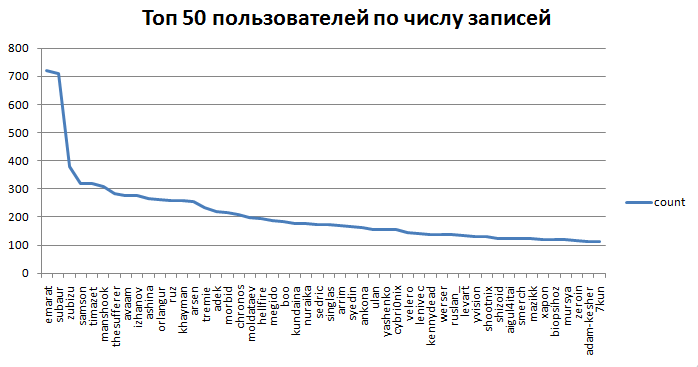
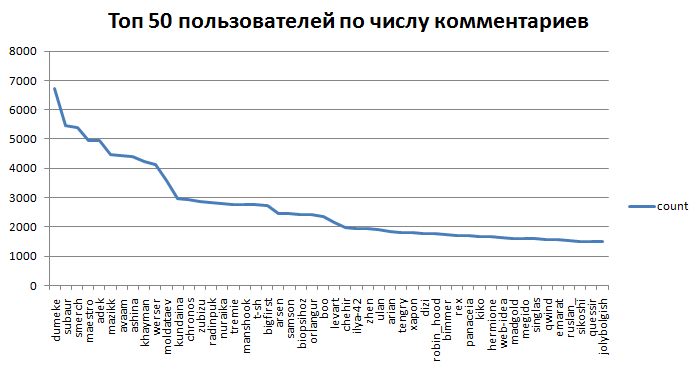
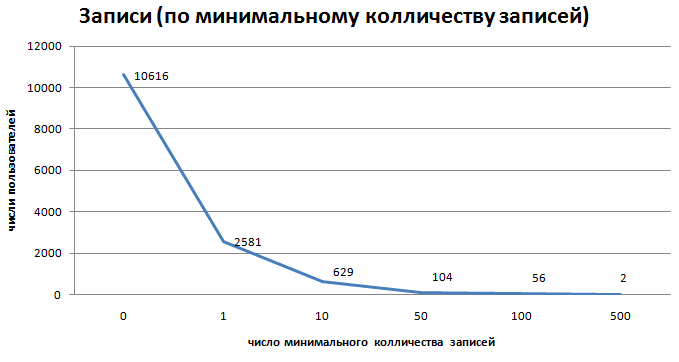
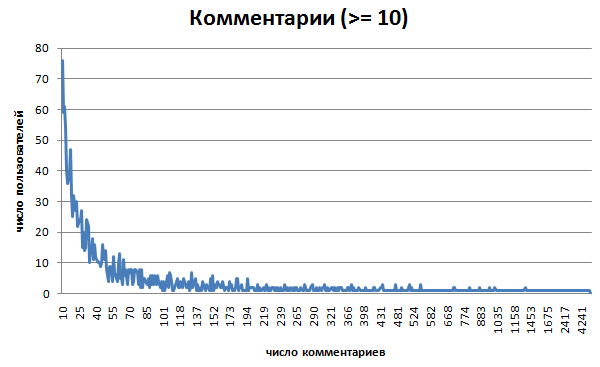
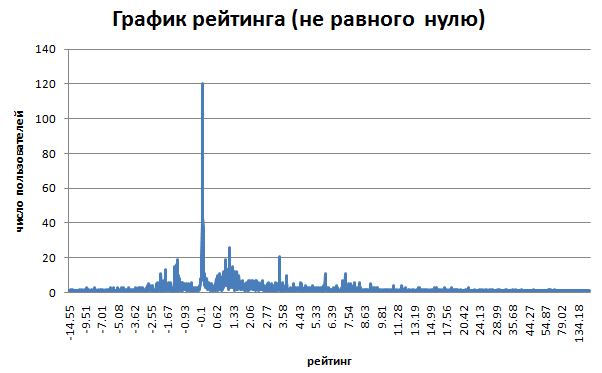
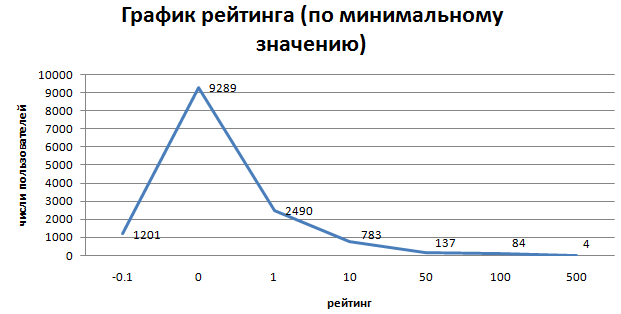
- 13989 зарегистрированных пользователей
- 3372 пользователя написавших хотябы одну запись
- 5445 пользователей написавших хотябы одну запись или один коммент
- 38777 записей
- 388484 комментария
- 20% пользователей написали 98% всех записей (примечание: очень отличается от предыдущей версии, нужно проверить)
- 2% пользователей написали 60% всех записей
- 20% пользователей написали 99% всех комментариев (примечание: очень отличается от предыдущей версии, нужно проверить)
- 2% пользователей написали 73% всех комментариев
- 46593 - баланс(сумма) рейтинга по всей системе(у всех пользователей)
- 50278 - сумма положительного рейтинга по всей системе
- 20% пользователей имеют 50051 всего положительного рейтинга
- 2% пользователей имеют 28277 всего положительного рейтинга
Как были получены данные
- источник: веб представление yvision.kz. Вся использованная информация доступна каждому пользователю сети интернет.
- инструменты: 80 строк Python кода для извлечения и фильтрации данных, Excel для анализа и графиков.
Что хотелось бы добавить:
- анализ связей между пользователями
- динамику изменения рейтинга для каждого пользователя втечении времени
- что ещё? есть идеи? делитесь!