

Решил посмотреть на Proxmox. Как вы помните, я уже ставил oVirt и vSphere. Теперь пришла очередь Proxmox...
Proxmox Virtual Environment (Proxmox VE) - это система управления виртуализацией с открытым исходным кодом основанная на дистрибутиве Debian. В качестве гипервизоров используются KVM и LXC. Если вам потребовалось создать кластер высокой доступности, посмотрите в сторону Proxmox, может быть это решение вам подойдет.
В реальной среде чтобы немного ускорить работу дисковой подсистемы, рекомендуется использовать связку из mdadm + lvmcache (на SSD) + xfs (ext4) + qcow2. Это позволить поднять IOP's и даст возможность использовать снапшоты.
В записке будут рассмотрены такие фичи кластера как:
- Живая миграция
- Создание контейнеров и виртуальных машин
Записка пока не полная.
СОДЕРЖАНИЕ
1. Установка Proxmox
1.1. Закачка ISO образа Proxmox VE4.2
1.2. Установка на два сервера кластера
1.3. Обновляем Proxmox
1.4. Убираем всплывающее окошко
1.5. Настраиваем имена хостов
2. Подготавливаем общее хранилище
2.1. Устанавливаем DRBD
2.2. Создаем новый раздел на диске sdb
2.3. Настраиваем DRBD
3. Создаем кластер и делаем первый хост мастером кластера
3.1. Добавляем в кластер второй хост
4. Создание контейнера
5. Создание виртуальной машины
6. Кластерные фичи
6.1. Живая миграция
6.2. Настраиваем фенсинг
7. Резервное копирование и восстановление ВМ
8. Ошибки DRBD
В начале установим Proxmox, после чего, настроим сетевой RAID массив на основе DRBD. С помощью DRBD создадим общее хранилище данных из жестких дисков каждого хоста гипервизора. Далее будет показано как создавать виртуальные машины, следом рассмотрим пример живой миграции. Мой тестовый кластер состоит из двух машин, для начала этого хватит.
Для тестирования виртуализации от Proxmox был установлен тестовый стенд на базе старого доброго KVM который кстати использовался для запуска oVirt.
1. Установка Proxmox
В этом разделе установим Proxmox на два сервера (ноды) нашего кластера. Сперва закачаем установочный ISO образ, далее начнем ставить его параллельно на ноды, после установки произведем базовые настройки системы.
1.1. Закачка ISO образа Proxmox VE4.2
Зайдите по ссылке:
https://www.proxmox.com/en/downloads/category/iso-images-pve

Нажмите на кнопке Download, как на картинке. И скачайте образ - proxmox-ve_4.2-725d76f0-28.iso
Запишите его на болванку.
1.2. Установка на две ноды кластера
В этом разделе пойдет речь о установке системы управления виртуализацией Proxmox.
Устанавливаем с болванки Proxmox на два сервера которые будут в кластере. Установка одинаковая, поэтому нет смысла выкладывать одни и те же скриншоты.

Выбираем - "Install Proxmox VE"

Здесь нажимаем - "I agree"

Нажимаем Next
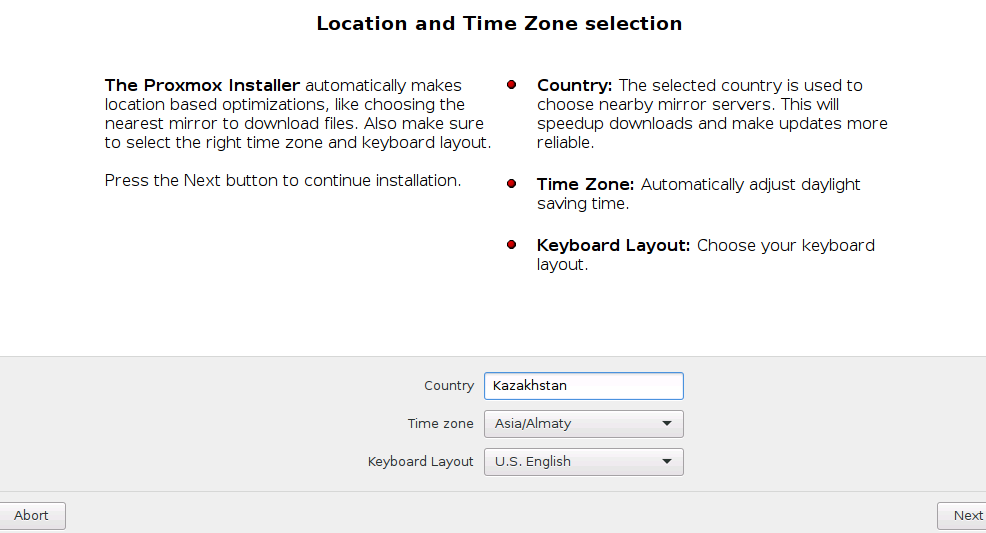
Выбираем Country - Kazakhstan
Time zone - Asia/Almaty
Раскладка - English
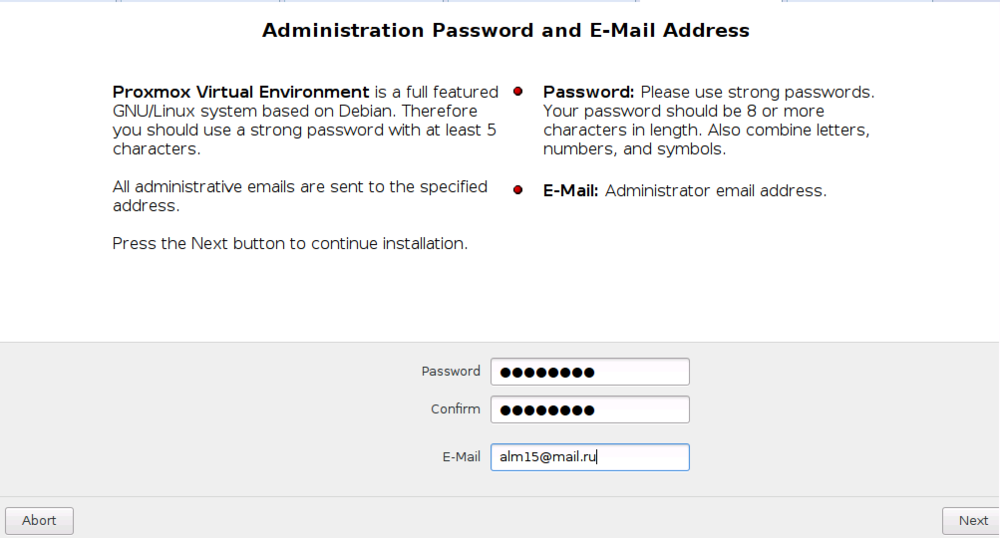
Здесь задаем пароль администратора и указываем его e-mail адрес.
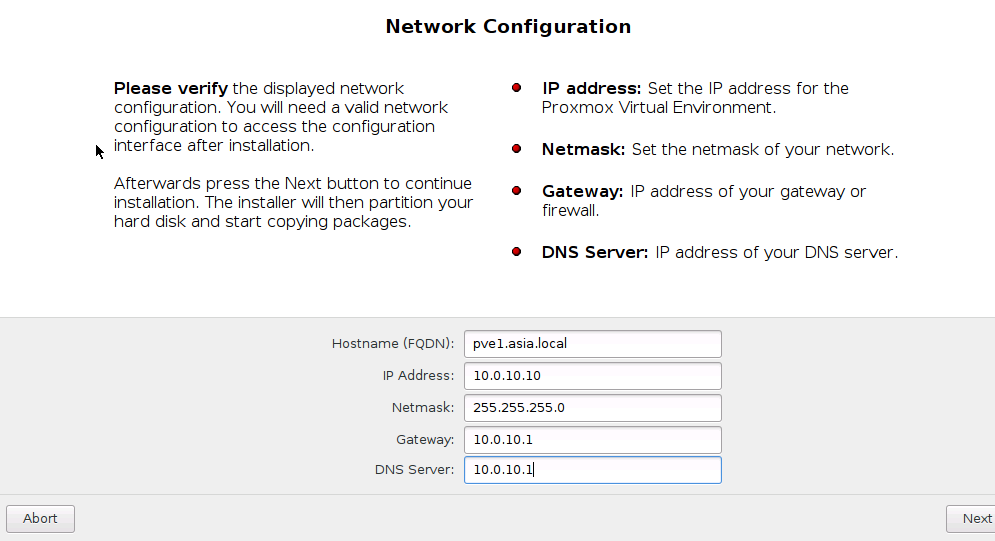
А здесь указываем имя хоста и другие сетевые параметры. Первый хост я обозвал как pve1.asia.local и дал ему IP адрес 10.0.10.10. Второму хосту дадим имя pve2.asia.local и IP адрес 10.0.10.11

Процесс создания разделов, форматирования и установки Proxmox. Сам Proxmox базируется на операционной системе Debian. Получается мы ставим кастомизированый Debian разработчиками Proxmox, плюс управляющий софт виртуализации.
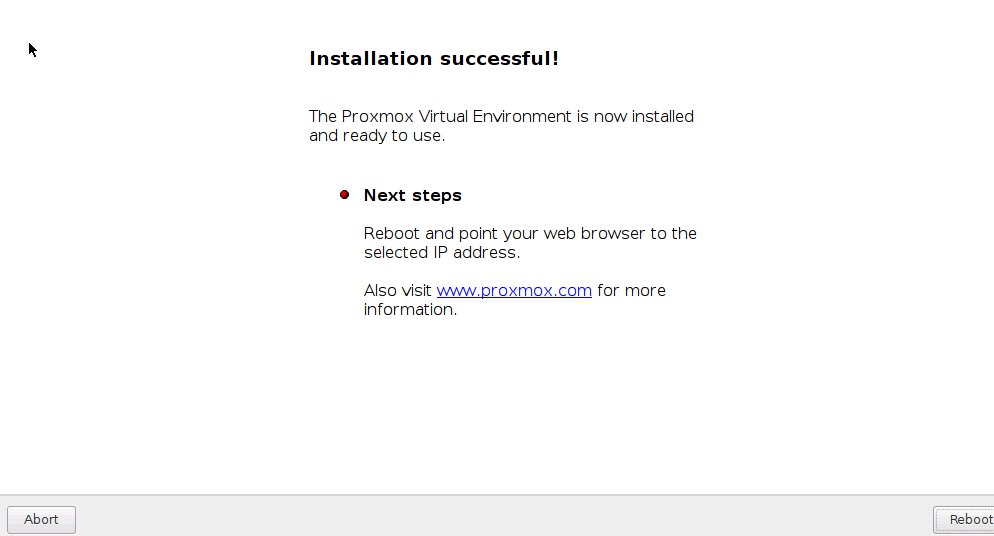
Конечное окно, где нас уведомляют, что процесс установки прошел успешно. И мы можем перезагрузить сервер.

После перезагрузки запросят пароль административной учетной записи - root.
Его мы задали во время установки Proxmox.
В верхней строке нам подсказывают что доступ к веб интерфейсу Proxmox есть по адресу https://ваш_IP:8006
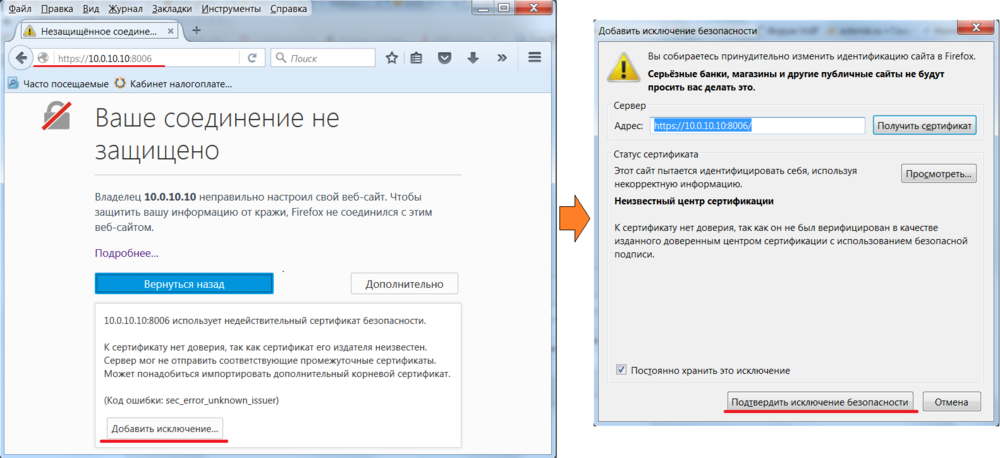
Соединение с веб интерфейсом Proxmox идет по само под писаному сертификату, поэтому требуется добавить исключение.
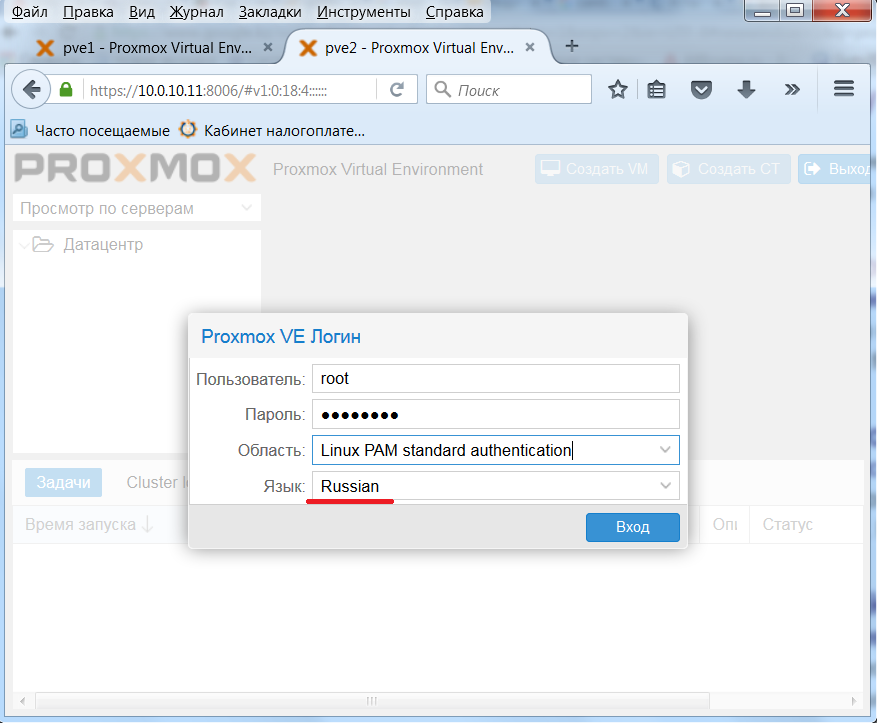
Вводим логин root и пароль который мы задавали при установке.
Язык интерфейса выбираем русский.
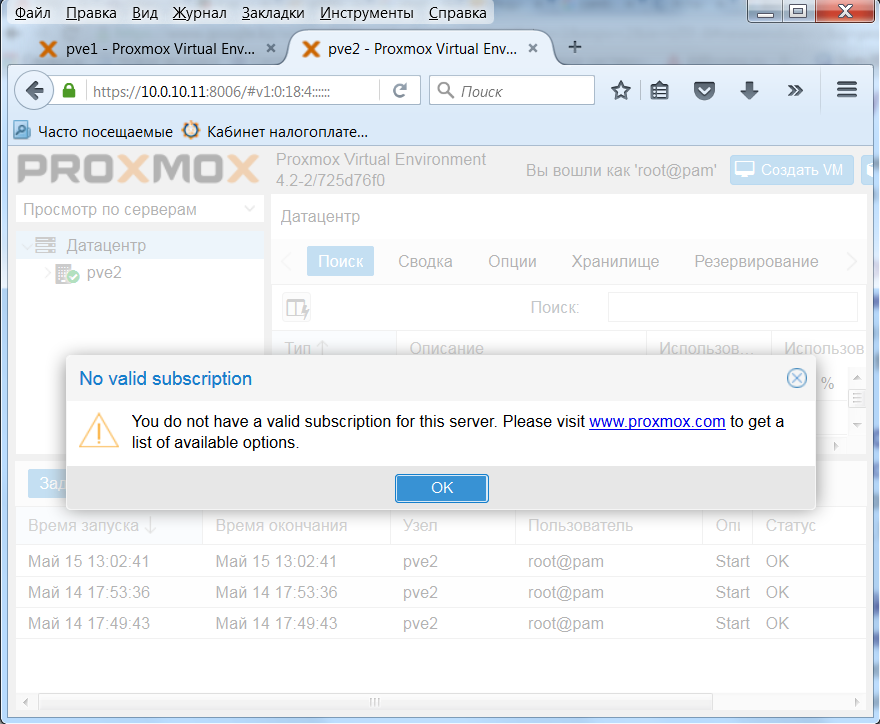
Всплыло окошко что у нас нет платной подписки. Оно всплывает всегда при входе в веб интерфейс.
1.3. Обновляем Promox
Убираем платный репозиторий:
# mv /etc/apt/sources.list.d/pve-enterprise.list /tmp
И добавим репозиторий сообщества:
# cat >> /etc/apt/sources.list.d/proxmox.list << EOF
deb http://ftp.debian.org/debian jessie main contrib
deb http://download.proxmox.com/debian jessie pve-no-subscription
deb http://security.debian.org/ jessie/updates main contrib
EOF
# aptitude update && aptitude full-upgrade
1.4. Убираем всплывающее окошко
Сообщение не критичное, его можно убрать, отредактировав файл /usr/share/pve-manager/ext6/pvemanagerlib.js
Редактируем его через sed:
# sed -i.bak "s/data.status !== 'Active'/false/g" /usr/share/pve-manager/ext6/pvemanagerlib.js
С помощью sed был открыт файл usr/share/pve-manager/ext6/pvemanagerlib.js
И в следующем условии:
if (data.status !== 'Active') { Ext.Msg.show({ title: gettext('No valid subscription'), icon: Ext.Msg.WARNING, msg: PVE.Utils.noSubKeyHtml, buttons: Ext.Msg.OK, callback: function(btn) { if (btn !== 'ok') { return; } orig_cmd(); }Произведены изменения - поменялось значение условие (data.status !=='Active') на (false):
if (false) {
1.5. Настраиваем имена хостов
Далее отредактируем файл /etc/hosts на двух хостах, чтобы он был примерно следующего вида:
# nano /etc/hosts
127.0.0.1 localhost.localdomain localhost
10.0.10.10 pve1.asia.local pve1 pvelocalhost
10.0.10.11 pve2.asia.local pve2 pvelocalhost
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
ff02::3 ip6-allhosts
Примечание: CTRL + O - сохранить файл и CTRL + X - выход с редактора Nano
В этом файле у меня две строки помеченные жирным шрифтом.
На всякий случай перезапустим сетевую службу:
# /etc/init.d/networking restart
2. Подготавливаем общее хранилище
Здесь создадим отказоустойчивое хранилище из свободных дисков каждого сервера. Я буду опираться на дисковой подсистеме с двумя HDD на каждом сервере кластера. На первом HDD каждого сервера будет система, а судьба второго - хранение виртуальных машин. Допустим, что объем второго HDD каждого сервера всего 20Гб. Его то будем использовать для хранения ВМ. Чтобы данные были одинаковы, настроим DRBD, это позволит создать сетевой рейд уровня 1.
В Linux каждый sata диск имеет примерное имя sda, sdb, sdc и т.д. Получается первый физический диск с именем sda, второй отдельный диск с именем sdb.
Когда вы создаете первый раздел на диске sda, ему присваивается имя sda1. Аналогично для диска sdb, будет раздел sdb1. Мы создадим раздел на диске sdb, и ему автоматически будет присвоен идентификатор sdb1.
2.1. Устанавливаем DRBD
Повторяем что здесь написано на обоих серверах.
Установим нужные программы:
# apt-get install drbd8-utils parted -y
2.2. Создаем новый раздел на диске sdb
Эта операция повторяется на двух серверах. Проверяем какие HDD у нас имеются в системе:
# fdisk -l | grep sd
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
/dev/sda1 34 2047 2014 1007K BIOS boot
/dev/sda2 2048 262143 260096 127M EFI System
/dev/sda3 262144 62914526 62652383 29.9G Linux LVM
Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors
В выводе видим два SATA HDD, один 30Гб - на нем стоит Proxmox, другой диск 20Гб - пустой.
Сперва удалим все с этого диска через parted:
# parted /dev/sdb mklabel msdos
Примечание: Если у вас появляется сообщение - "Re-reading the partition table failed.: Device or resource busy". Значить на вашем диске есть LVM тома, удалите их с помощью команд "lvchange -a n drbdpool" (или drbdvg) и "lvremove drbdpool" (или drbdvg). Введя "pvscan /dev/sdb1" можно узнать какой LVM том требуется удалить. Также если появляется ошибка:
Error: Partition(s) 1 on /dev/sdb have been written, but we have been unable to inform the kernel of the change, probably because it/they are in use. As a result, the old partition(s) will remain in use. You should reboot now before making further changes. Ignore/Cancel?
Значить к разделу обращается какая-та программа, в нашем случае это демон DRBD. Его требуется остановить - "/etc/init.d/drbd stop"
Создадим раздел на 20Гб HDD:
# fdisk /dev/sdb
Command (m for help): n -> p -> 1 -> enter -> enter
Command (m for help): t -> 8e
Command (m for help): p
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
Раздел создан.
2.3. Настраиваем DRBD
Приведем конфигурационные файлы DRBD к следующему виду:
# mv /etc/drbd.d/global_common.conf /etc/drbd.d/global_common.conf.orig
И создаем новый конфиг файл global_common.conf
# nano /etc/drbd.d/global_common.conf
global { usage-count no; }common { disk { c-plan-ahead 0; resync-rate 30M; } syncer { verify-alg md5; } handlers { out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root"; }}# nano /etc/drbd.d/r0.res
resource r0 { protocol C; startup { wfc-timeout 0; # non-zero wfc-timeout can be dangerous (http://forum.proxmox.com/threads/3465-Is-it-safe-to-use-wfc-timeout-in-DRBD-configuration) degr-wfc-timeout 60; become-primary-on both; } net { cram-hmac-alg sha1; shared-secret "my-secret"; allow-two-primaries; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; #data-integrity-alg crc32c; # has to be enabled only for test and disabled for production use (check man drbd.conf, section "NOTES ON DATA ") } on pve1 { device /dev/drbd0; disk /dev/sdb1; address 10.0.10.10:7788; meta-disk internal; } on pve2 { device /dev/drbd0; disk /dev/sdb1; address 10.0.10.11:7788; meta-disk internal; } disk { # no-disk-barrier and no-disk-flushes should be applied only to systems with non-volatile (battery backed) controller caches. # Follow links for more information: # http://www.drbd.org/users-guide-8.3/s-throughput-tuning.html#s-tune-disable-barriers # http://www.drbd.org/users-guide/s-throughput-tuning.html#s-tune-disable-barriers no-disk-barrier; no-disk-flushes; }}
Здесь главное вписать имена хостов и их IP адреса.
После создания раздела и настройки DRBD, запускаем DRBD на двух серверах:
# /etc/init.d/drbd start
[ ok ]Starting drbd (via systemctl): drbd.service.
И создаем ресурс:
# drbdadm create-md r0
New drbd meta data block successfully created.Примечание: Если выходит ошибка "Operation refused", запустите команду parted "/dev/sdb1 mklabel msdos". Еще, может возникнуть ошибка "peer connection already exists". То тогда перезапускаем DRBD на обоих серверах "/etc/init.d/drbd start". Плюс, бывает что ресурс r0 уже был создан - "peer connection already exists ", в таком случае, необходимо отсоединить (удалить) этот ресурс и создать его заново, команды для отсоединения - "drbdadm disconnect r0" и "drbdadm detach r0".
Теперь делаем его активным:
# drbdadm up r0
Только на первом мастер сервере:
По умолчанию DRBD создает два ведомых сервера (secondary), что нас не устраивает. Мы должны назначить один сервер как мастера (primary):
# drbdadm -- --overwrite-data-of-peer primary r0
Создаем физический PV (PhysicalVolume) том LVM:
# pvcreate -ff /dev/drbd0
Если команда "pvcreate" не проходит с ошибкой
WARNING: PV 73IGeR-Uouv-gR7j-bbdV-7snr-G90J-WzW5ZV on /dev/sdb1 was already found on /dev/drbd0.
или
Cannot use device /dev/drbd0 with duplicates.
То значить вам потребуется отредактировать файл /etc/lvm/lvm.conf, а именно строчку:
global_filter = [ "r|/dev/zd.*|", "r|/dev/mapper/pve-.*|", "r|/dev/sd.*|"]
Жирным шрифтом помечены изменения которые надо сделать.
Также есть трабл со стартом служб DRBD и LVM, после рестарта хостов DRBD не может найти диски для синхронизации. Помогает команда:
"lvchange -a n drbdpool"
Теперь создадим группу томов (Volume group) drbdvg:
# vgcreate drbdvg /dev/drbd0
Проверяем, идет ли синхронизация дисков двух серверов:
# watch cat /proc/drbd
Every 2.0s: drbdadm status Sun May 29 11:00:33 2016
r0 role:Primary
disk:UpToDate
pve2 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:18.63
Теперь добавляем созданную группу томов только на первом хосте:
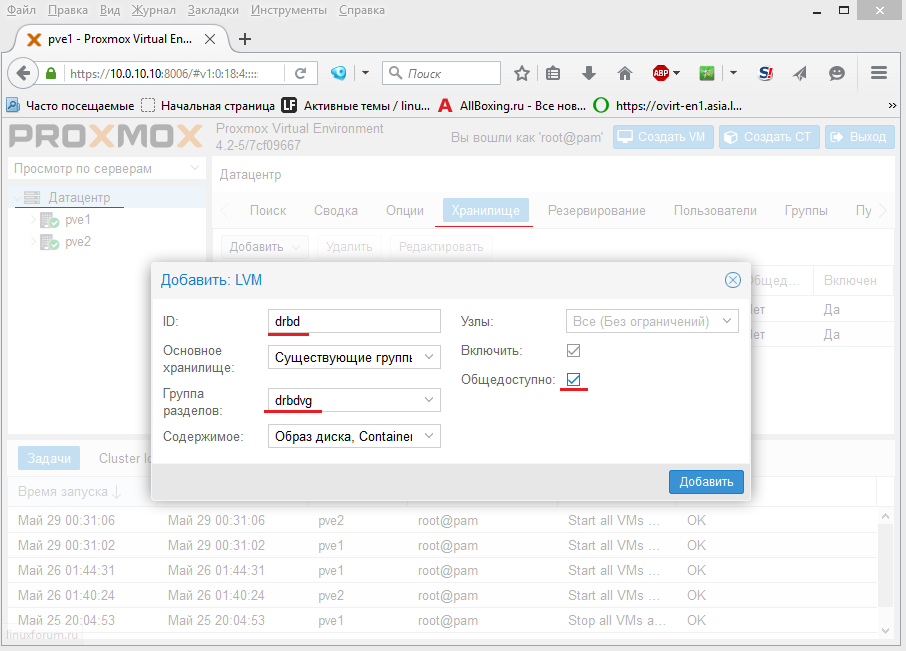
Здесь вводим/выбираем:
- ID: drbd
- Группа разделов: drbdvg
- Общедоступно: галочка
Нажимаем Добавить.
Теперь у нас есть общее хранилище для виртуальных машин, а это значить, будет работать живая миграция.
Обязательно при создании ВМ указывайте хранилище DRBD, чтобы заработала живая миграция.
3. Создаем кластер и делаем первый хост мастером кластера
Команда для создания кластера на первом хосте:
# pvecm create cluster1
Corosync Cluster Engine Authentication key generator.
Gathering 1024 bits for key from /dev/urandom.
Writing corosync key to /etc/corosync/authkey.
Здесь мы создали кластер с именем "cluster1"
3.1. Добавляем в кластер второй хост
На втором хосте вводим команду с IP адресом мастер хоста, тем самым добавляя второй хост в кластер "cluster1"
# pvecm add 10.0.10.10
The authenticity of host '10.0.10.10 (10.0.10.10)' can't be established.
ECDSA key fingerprint is be:5e:43:54:e3:80:c0:6e:39:c0:1b:5e:65:a4:4c:02.
Are you sure you want to continue connecting (yes/no)? y
Please type 'yes' or 'no': yes
root@10.0.10.10's password:
copy corosync auth key
stopping pve-cluster service
backup old database
waiting for quorum...OK
generating node certificates
merge known_hosts file
restart services
successfully added node 'pve2' to cluster.
Запросят пароль root от первого хоста.
После этой операции кластер создан с двумя членами:
4. Создание контейнера
Создадим тестовый LXC контейнер с CentOS 7
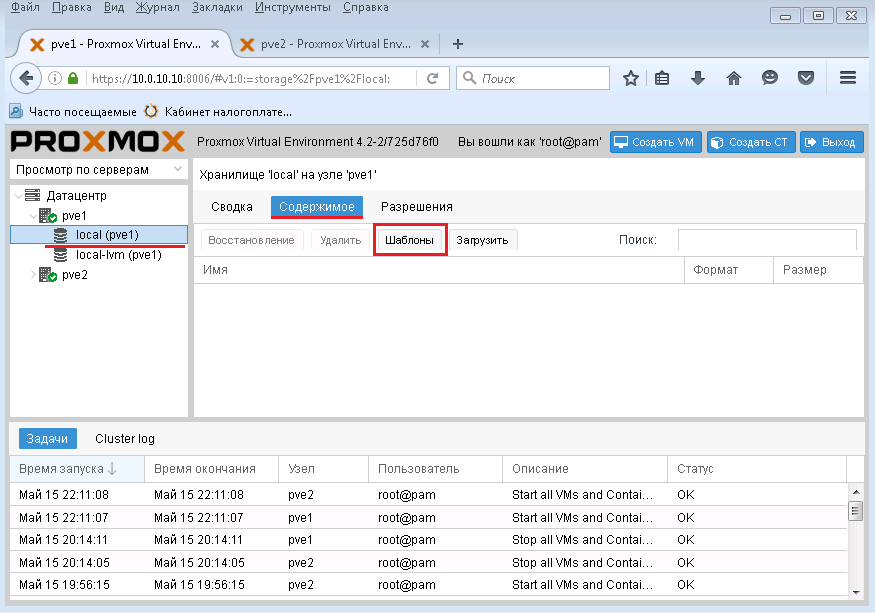
Заходим в pve1 -> local (pve1) -> Содержимое -> Шаблоны
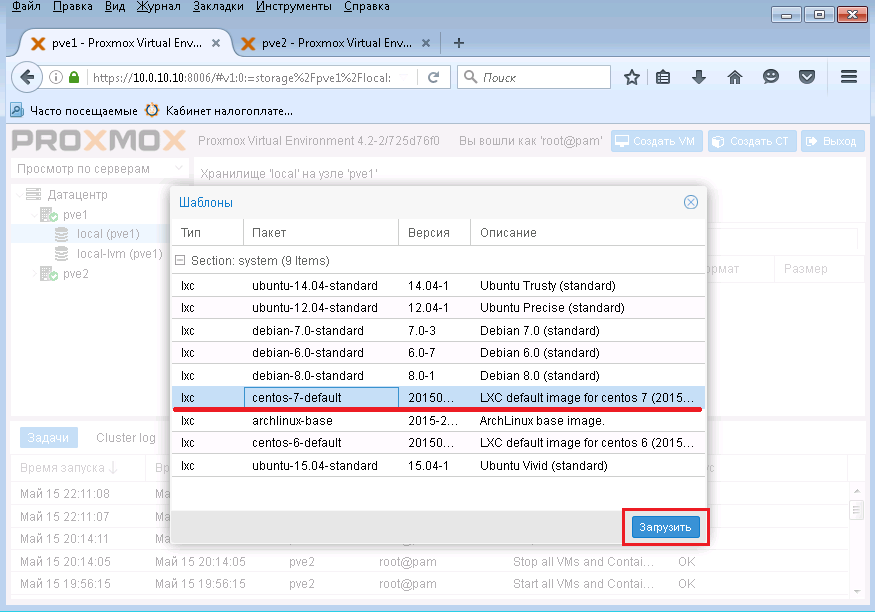
Выбираем "CentOS-7-default" и нажимаем Загрузить. После чего, начнется загрузка шаблона с CentOS на ваш Proxmox.
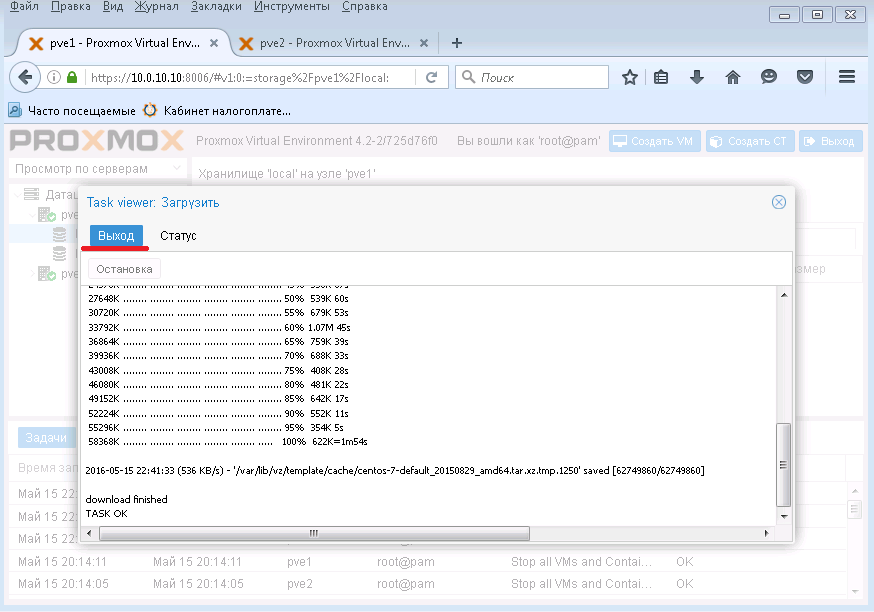
Нажимаем Выход и далее мы создадим ВМ с помощью этого шаблона.
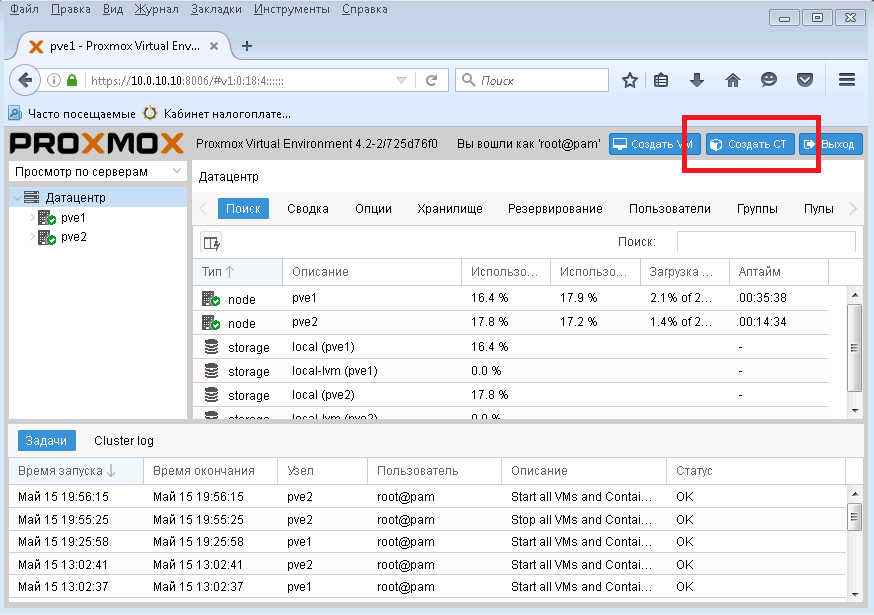
Кликним "Создать СТ"
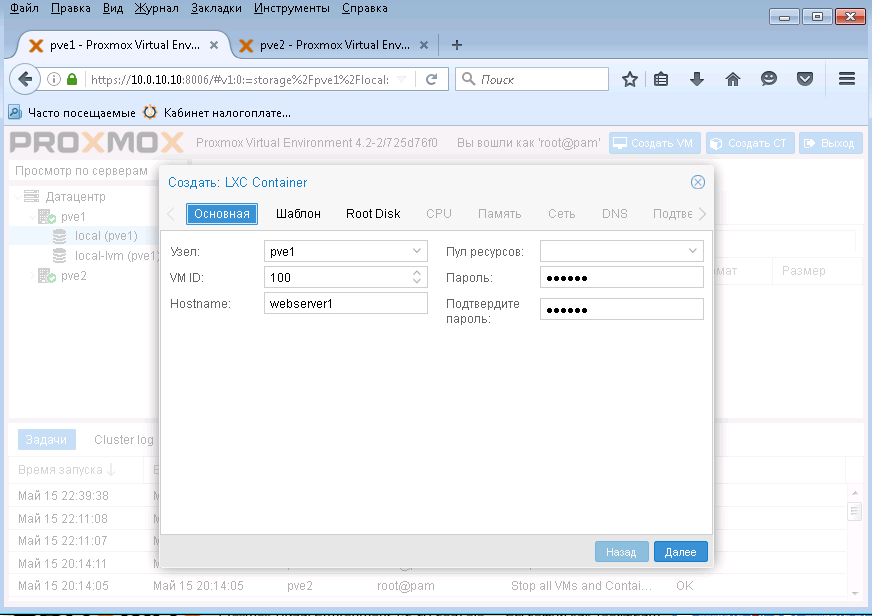
Здесь задаем пароль и хостнейм. Нажимаем Далее
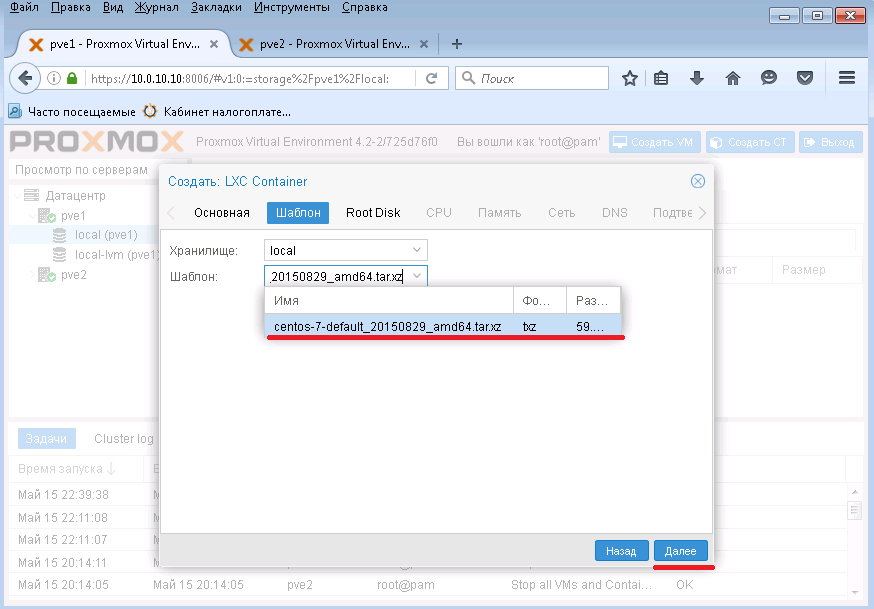
В поле шаблон выбираем закачанный шаблон с CentOS 7 и нажимаем Далее.
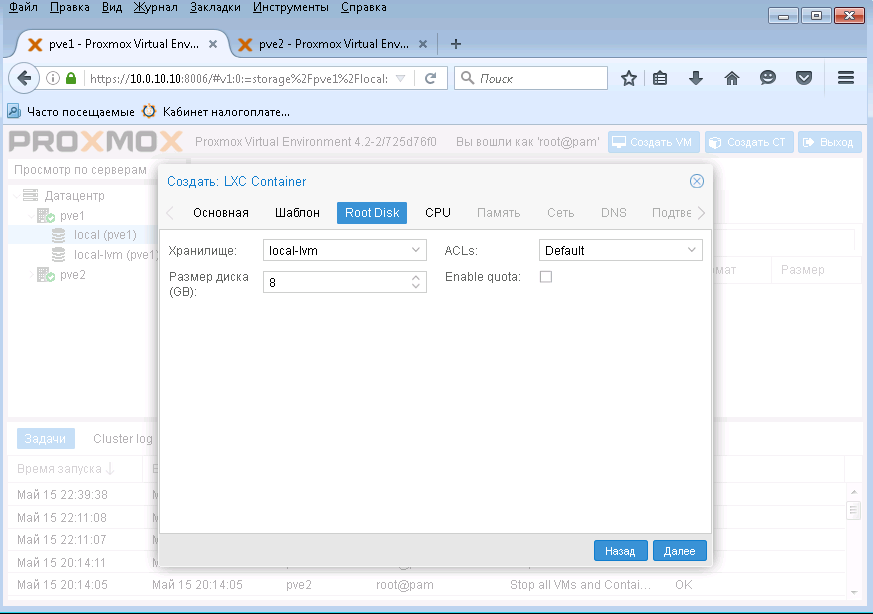
Здесь можно задать хранилище и объем дискового места под создаваемый контейнер. А также можно включить ACL.
Нажимаем Далее.
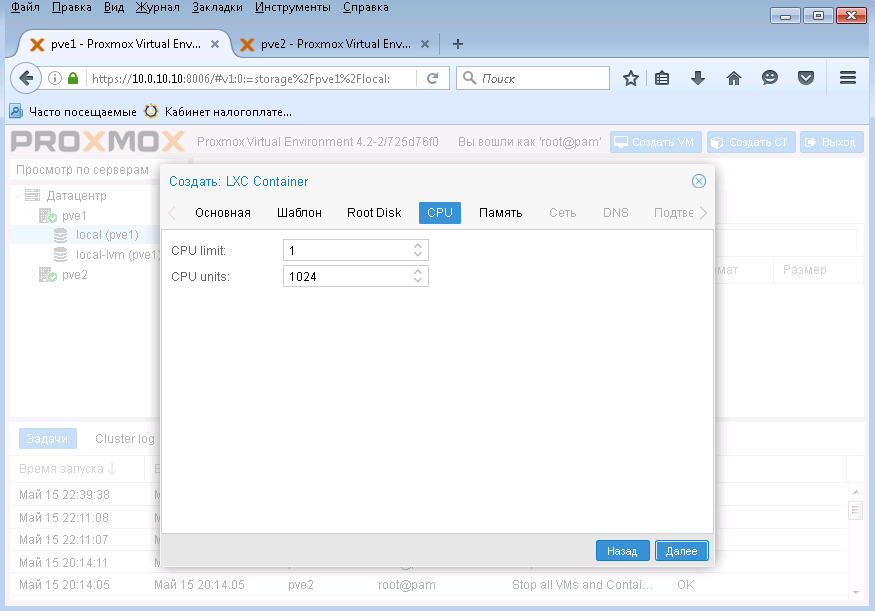
А здесь задаем какое количество ресурсов процессора будет отведено для контейнера.
Я оставил все по умолчанию и нажал Далее.
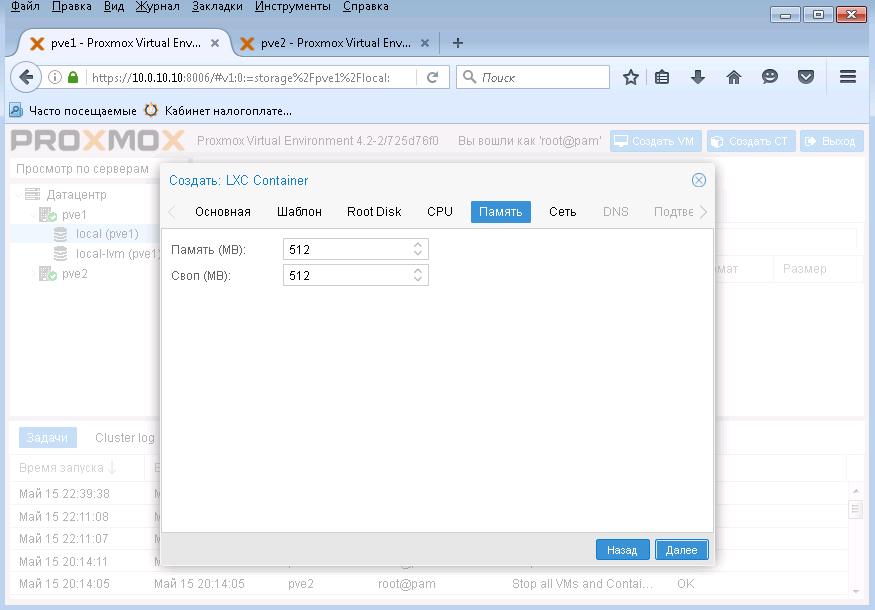
В этом окне указываем количество ОЗУ для контейнера и нажимаем Далее.
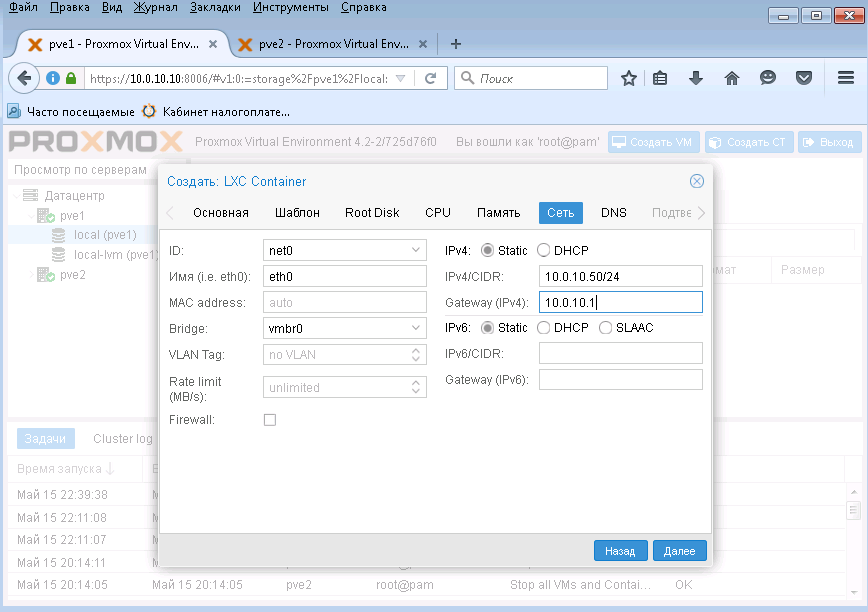
Сетевые настройки - указываем статический IP адрес в формате CIDR и адрес шлюза. По умолчанию используется мост к вашему физическому адаптеру, меня это устроило. Нажимаем Далее.
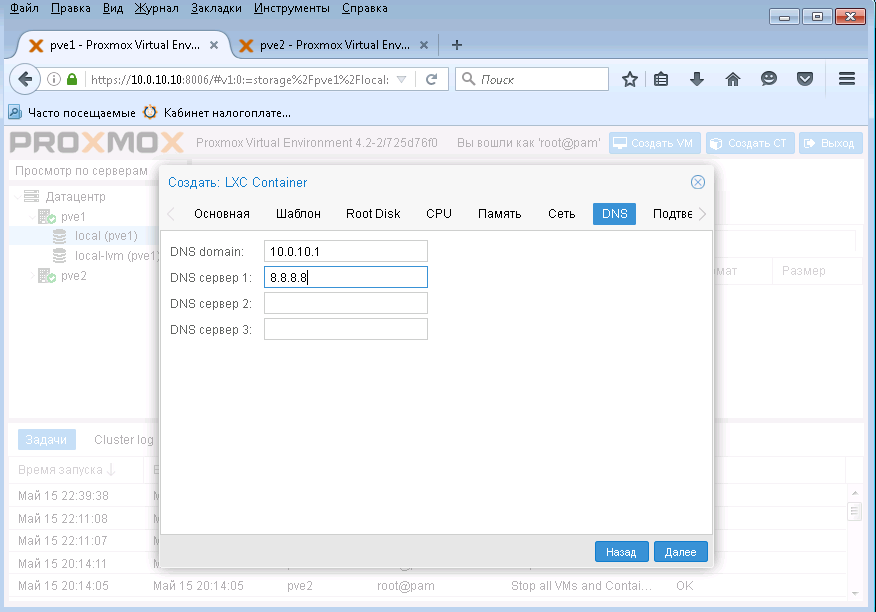
Задаем адреса DNS серверов и нажимаем Далее.

Подтверждаем настройки и нажимаем кнопку Завершить.
Контейнер создан - нажимаем Выход
А теперь запустим наш свеже созданный контейнер.
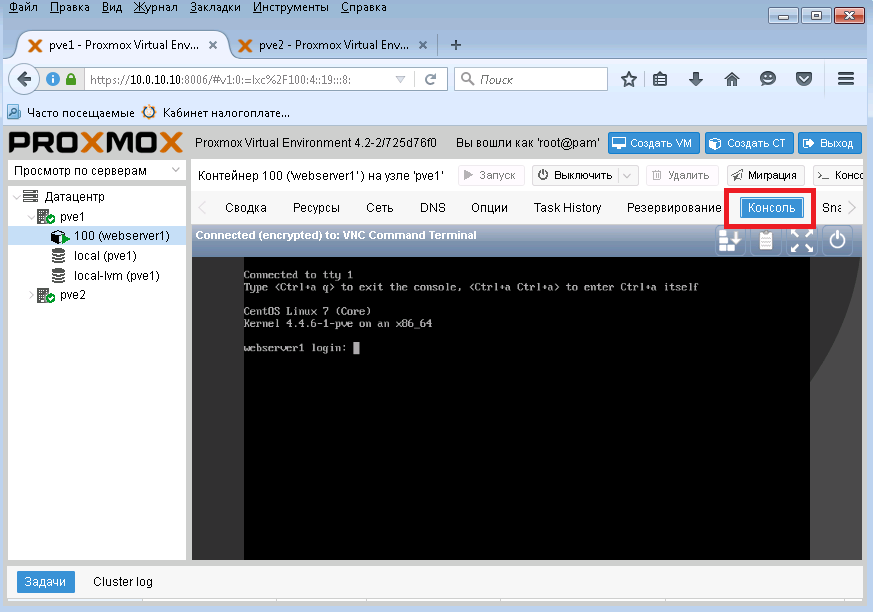
Чтобы увидеть консоль, щелкним одноименную кнопку. Вот и все - контейнер создан!
5. Создание виртуальной машины
Теперь создадим тестовую виртуальную машину с операционной системой TinyCore Linux.
Для этого закачаем ISO образ TinyLinux в /var/lib/vz/template/iso
# cd /var/lib/vz/template/iso
# wget http://tinycorelinux.net/6.x/x86/release/TinyCore-current.iso
И потом уже начнем создавать ВМ:

Щелкним Создать ВМ как на картинке.
Вводим имя - TinyLinux и нажимаем Далее.

Указываем что создается Linux виртуальная машина и нажимаем Далее.
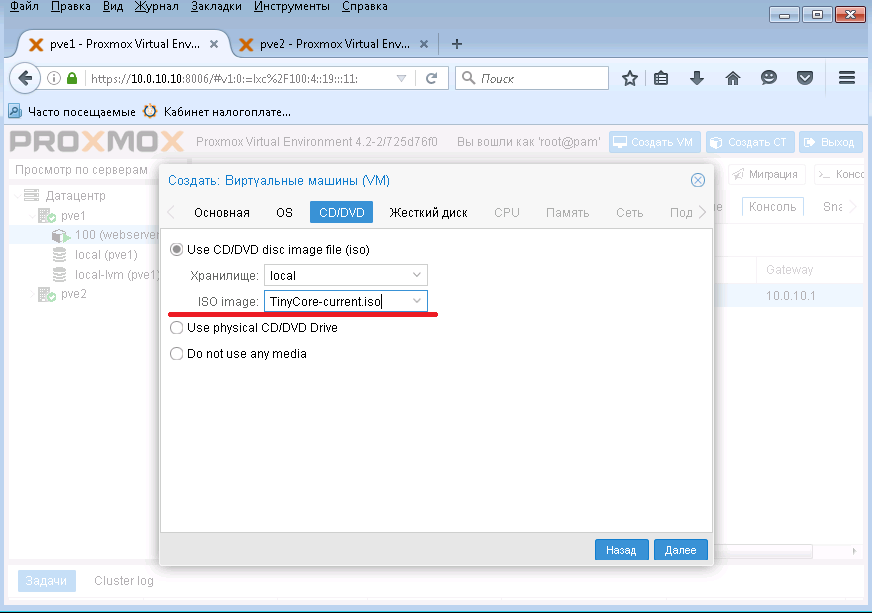
А здесь ставим наш закачанный ISO образ TinyCore Linux и нажимаем Далее.
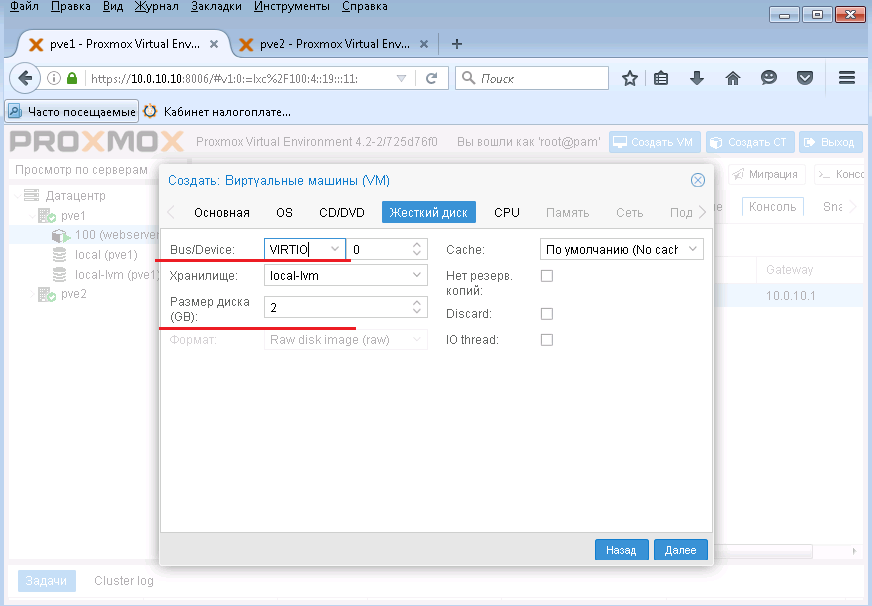
Задаем VIRTIO контроллер для дисков, а также указываем объем виртуального жесткого диска и нажимаем Далее.
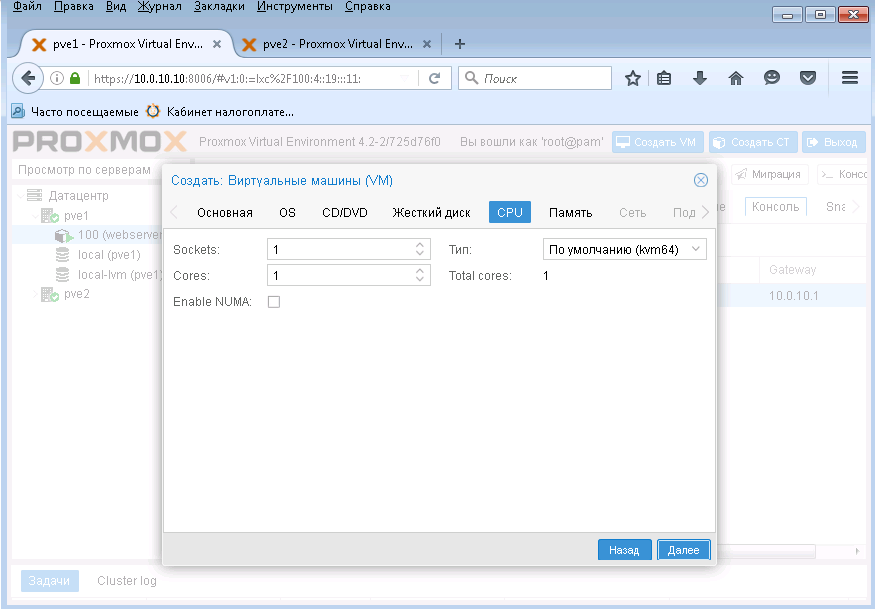
Здесь я все оставил по умолчанию, хватит одного ядра процессора и нажимаем Далее.
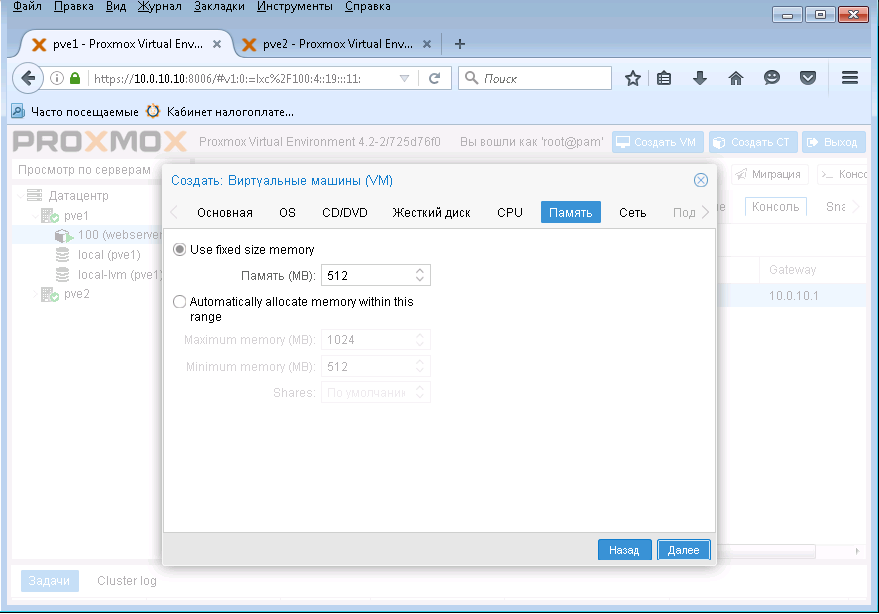
Указываем объем ОЗУ для ВМ и нажимаем Далее.
Настройка сетевого адаптера - я оставил все по умолчанию.

Окно подтверждения - нажимаем Завершить.

По умолчанию ВМ не запускается автоматом, поэтому выделяем ее и нажимаем кнопку Запустить.

Если нажать кнопку Консоль, мы увидим работу ВМ как на картинке.
Полноэкранный режим вывода, кнопка ESC - выход с него.
На этом все по созданию ВМ.
6. Кластерные фичи
Рассмотрим живую миграцию. Чтобы посмотреть как это работает, потребуется удовлетворить следующие требования, кстати эти требования, почти одинаковы для всех систем управления виртуализацией:
- Одинаковое железо на серверах, например одна модель процессора, как по частоте, так и по ядрам. То есть например процессор Xeon E3 1230v3 должен быть установлен на обеих серверах кластера. Нельзя мешать разные процессоры, ставить Intel на одном, а на другом AMD.
- Количество ОЗУ должно быть одинаковое на обоих серверах кластера, например 32Гб на одном и другом. Чтобы хватало ресурсов на переезд виртуальных машин между гипервизорами. Представьте ситуацию если все ВМ работают на сервере с 32Гб в паре с сервером с 16Гб ОЗУ, и вот однажды первый сервер сгорел, все машины должны перезапуститься на втором сервере с 16Гб ОЗУ - ресурсов не хватило = проблема.
- Диски виртуальных машин обычно должны быть толстыми (постоянного объема).
- Центральное хранилище данных на котором должны хранится данные виртуальных машин (файлы жестких дисков, файлы с конфигурацией и т.д.). С доступом двух серверов кластера к этому хранилище данных.
- Настроенный фенсинг
- Синхронизация времени
- Виртуальная машина должна быть без диска в CDROM
- Есть и другие требования, но основные эти.
Примечание: Возможности живой миграции и высокой доступности не поддерживаются если вы используете контейнеры.
Можно сделать вариант кластера только из двух серверов (нод):
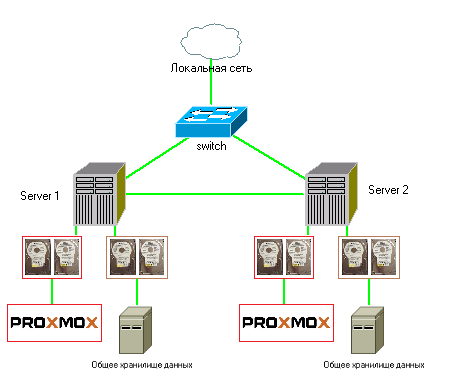
В этом примере, каждый сервер выполняет роль гипервизора и имеет хранилище, которое синхронизируется между двумя узлами. Обычно в таком случае, на серверах имеется 4 жестких диска. Из первых двух дисков создается программный массив для операционной системы (Proxmox), а два других - используются для общего хранилище данных, на котором будут располагаться виртуальные машины, из них также создается массив. Это как бы локальное реплицирумое хранилище между двумя нодами. Также сервера должны иметь по две сетевые карты, первые будут выходить в локальную сеть, а две другие соединять эти два сервера.
Второй вариант кластера с центральным хранилищем:
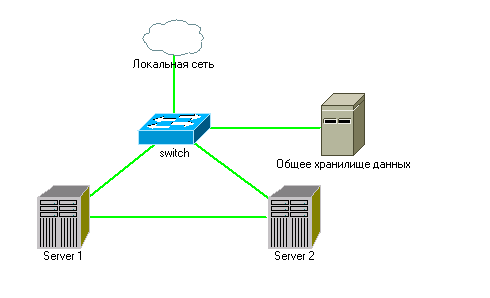
Здесь сервера 1 и 2 выполняют только одну роль - гипервизор. Данные виртуальных машин хранятся в хранилище, которое может быть продублировано (зависит от бюджета).
Рассмотрим бюджетный вариант кластера когда в наличии всего два сервера с 4-мя дисками в дисковой подсистеме на каждом. Обычно, из первых двух жестких дисков делают программный рейд массив под систему, а остальные два отдают под хранилище для виртуальных машин. Так как требуется по 4шт. HDD на каждый сервер. Я решил показать аналогичный случай с серверами имеющими в своей конфигурации по два HDD на сервер.
6.1. Живая миграция
Подопытная ВМ для живой миграции TinyCore Linux, посмотрим как она качует с хоста на хост. До миграции обязательно уберите при соединенный ISO образ.
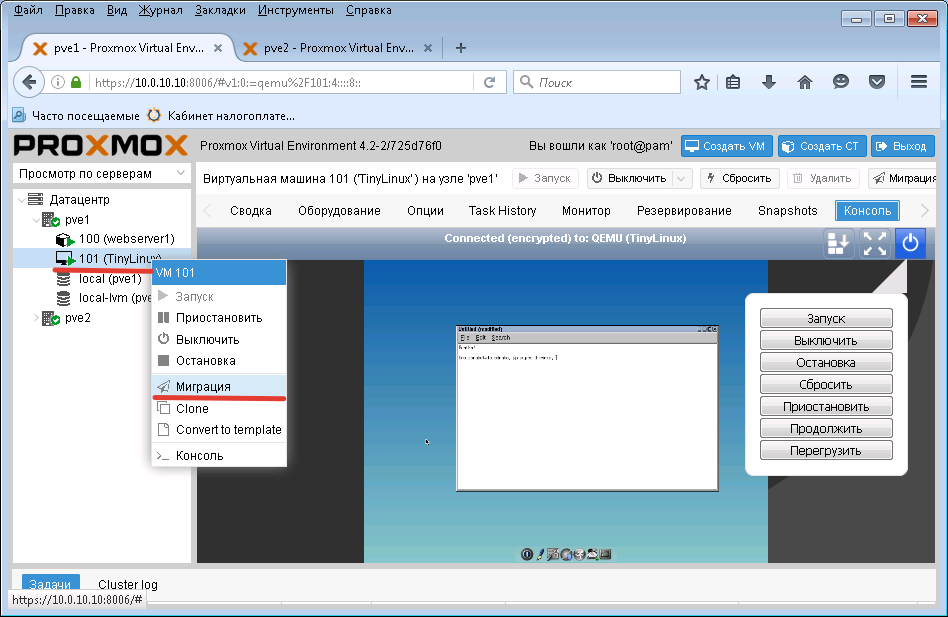
Нажимаем правую кнопку мышки на виртуальной машине TinyCore Linux и в контекстном меню выбираем Миграция.
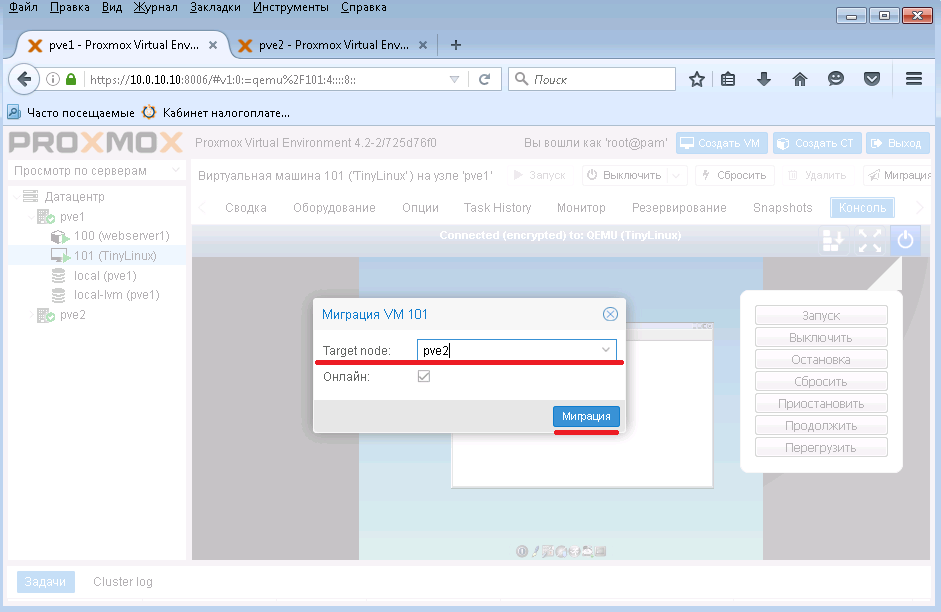
Выбираем хост с именем pve2 и нажимаем кнопку Миграция. После чего начнется процесс живой миграции с хоста pve1 на pve2.
6.2. Настраиваем фенсинг
К сожалению процесс фенсинга в версии Proxmox 4 автоматизирован через службу "watchdog", которая сама определяет какие железные механизмы перезапуска доступны. По идее если сервер например c HP iLO, в Proxmox будет выведен этот способ фенсинга. Watchdog может использовать модуль softdog, это программный механизм фенсинга. Работает он автоматически, например перестал работать сетевой адаптер, модуль softdog это определяет и после определенного таймаута перезапускает сервер или сетевую службу. Если произойдет Kernel Panic, такой способ не поможет. Поэтому желательно использовать аппаратный Watchdog.
Запустим программный watchdog:
# nano /lib/modprobe.d/blacklist_pve-kernel-4.4.10-1-pve.conf
Удалим строку(на двух серверах):
blacklist ipmi_watchdog
# systemctl restart watchdog-mux.service
# modprobe softdog
# systemctl status watchdog-mux.service
# nano /etc/default/pve-ha-manager
Перезагружаем сервер:
# reboot
И проверяем отключая сетевой интерфейс одного из серверов Proxmox:
# ifdown vmbr0
Внизу в ссылках есть статья по настройке аппаратного и программного watchdog.
7. Резервное копирование и восстановление ВМ
Процедура создания резервных копий, а также восстановление работы ВМ, описаны в мануале на официальном сайте. Вы можете настроить резервное копирование через веб интерфейс или использовать консольную утилиту vzdump. Внизу показан пример резервного копирования с помощью vzdump.
Резервное копирование делается с помощью команды vzdump. Приведу одну строчку с помощью которой можно сделать резервирование данных всех ВМ:
# vzdump --all --mode suspend --mailto root --mailto admin
Здесь:
--all - Говорит утилите vzdump сделать бекап всех ВМ
--mode suspend - задает режим резервного копирования с приостановкой работы ВМ (пауза)
--mailto root и --mailto admin - опции которые позволяют отправлять отчет на почтовые адреса root и admin
От себя отмечу, иногда может произойти не предвиденный случай с DRBD, и вы можете получить так называемый SPLIT BRAIN. Это когда теряется связь между узлами и каждый из них думает что он главный. То есть каждый хост пишет свои данные на свое локальное хранилище которое мы реплицируем, в итоге мы получаем разные данные на первом и втором хосте, так как данные уже не совпадают, и которые уже нельзя синхронизировать.
Когда связь между ними восстанавливается узел который первый обнаружил Split Brain, переходит в автономный режим (standalone). DRBD умеет автоматически уведомлять администратора в случае такой ситуации.
Восстановить работу DRBD можно в ручную перезалив данные с одного хоста на другой средствами DRBD.
Поэтому выводы такие:
- Делайте резервные копии
- Следите за работой DRBD - читайте логи
- Не используйте DRBD в режим Active/Active
- Между узлами иметь сетевое соединение 1Гбит и выше
8. Ошибки DRBD
New drbd meta data block successfully created.
open(/dev/sdb1) failed: Device or resource busy
Решение: всего скорей вы создали LVM разделы и теперь эти разделы управляются демоном LVM, поэтому надо удалить такие разделы командами "lvchange -a n drbdpool" и "lvremove drbdpool"
You need to either
* use external meta data (recommended)
* shrink that filesystem first
* zero out the device (destroy the filesystem)
Operation refused.
Решение: Отчистить раздел sdb1 - "parted /dev/sdb1 mklabel msdos"
DRBD Split Brain.
Решение:
Шаг 1: Стартуем DRBD в ручном режиме на обоих нодах (серверах)
Шаг 2: Определяем одну ноду как вторичную и отменяем записанные данные на ней
drbdadm secondary all
drbdadm disconnect all
drbdadm -- --discard-my-data connect all
Шаг 3: Определяем другую ноду как первичную и соединяем
drbdadm primary all
drbdadm disconnect all
drbdadm connect all
drbdadm primary disk1
Ссылки:
Кластерное хранилище в Proxmox. Часть первая. Fencing
Proxmox VE 2 cluster with DRBD (HA, Fencing)
Создание кластера на базе Proxmox 3.2 VE (cluster)
Виртуализация Proxmox VE 3.X (KVM, OpenVZ) в составе кластера с внешним хранилищем + HA
PROXMOX VE. КЛАСТЕР ИЗ 2-Х PROXMOX-ХОСТОВ
Proxmox VE 2 – быстрый старт в виртуализации
Pvcreate not detecting harddrives (Device /dev/abc not found (or ignored by filtering).
http://vasilisc.com/upgrade-proxmox-3-4-to-4
https://geekpeek.net/drbd-management-command-usage/
http://xiaocainiaox.blog.51cto.com/4484443/1200323
How to auto restart CentOS Linux server with software watchdog (softdog) to reduce server downtime