
Столкнулся с задачей: есть сайт который нужно клонировать, но на нем около 50 рубрик и больше 40 000 статей, и все эти записи нужно перенести на сайт клона.
"Остается запастись терпения и несколько месяцев свободного времени для переноса материалов в базу данных нового сайта" - подумал заказчик.
Но мы ведь программисты и не любим рутину, у нас долг такой "Облегчать людям жизнь", вот я и решил написать граббера который сам все сделает в течении одного часа, и сайт можно будет запускать! И в этом посте я расскажу и даже покажу как написать это на технологии ASP.NET с использованием языка C#. Поехали.
Инструменты.
Для данного опыта нам понадобится софт:
- Visual Studio 2010
- .Net Framework 4.0
В качестве парсера HTML воспользуемся HTML Agility Pack, но прежде чем парсить нам нужно сначала получить HTML, можно воспользоватся стандартным WebClient(), но далеко не секрет что сейчас все сайты усыпаны JavaScript который генерирует часть разметки, информации, а WebClient() к сожалению не может ждать пока отработает JS и только после этого забирать HTML. Значит нам он не подойдет. И на помощь приходит библиотека Watin!
Watin - библиотека которая помогает тестировать приложения, программируешь тест, и в реальном времени открывается браузер и выполняются различные нажатия кнопок ввод текст и т.д.
Но мы будем использовать её не совсем по назначению.
Начнем.
В Visual Studio создаем новое консольное приложение

Далее устанавливаем нужные библиотеки
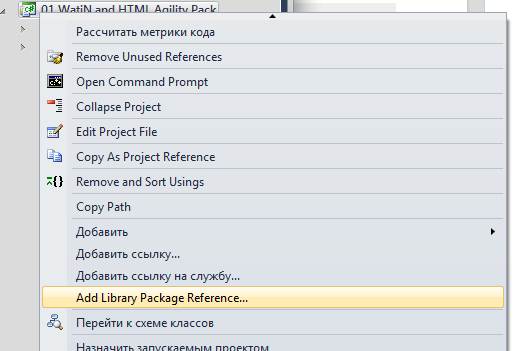
Открываем раздел "Online" и в строке поиска пишем "watin"
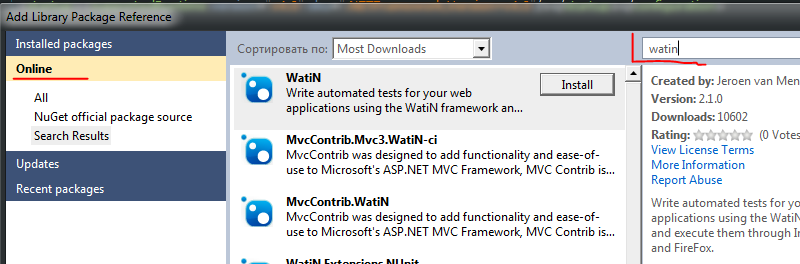
и жмем установить WatiN
Далее пишем в поиске HTMLAgilityPack и тоже устанавливаем
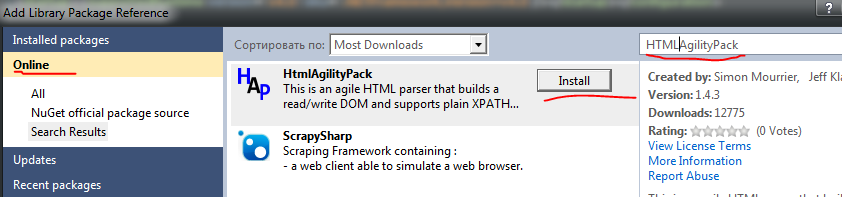
Установка библиотек завершена.
Далее добавляем файл конфигурации в наш проект с именем app.config
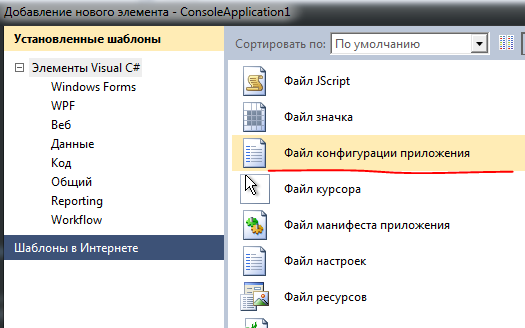
во внутрь файл положите это:
- <?xml version="1.0"?>
- <configuration>
- <startup><supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.0"/></startup></configuration>
Далее изменим конфигурацию приложения, в солюшене нажмем на Properties два раза
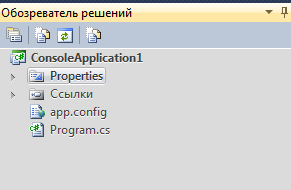
И изменим пункт "Требуемая версия .Net Framework" на ".Net Framework 4"
далее открываем Program.cs и подключаем нужные библиотеки перед class Program{ }
- using HtmlAgilityPack;
- using System;
- using WatiN.Core;
перед static Main указываем что это однопоточное приложение
- [STAThread]
В итоге у вас должно получится следующее
- namespace ConsoleApplication1
- {
- using HtmlAgilityPack;
- using System;
- using WatiN.Core;
- class Program
- {
- [STAThread]
- static void Main()
- {
- }
- }
- }
*namespace может отличатся
далее в Main(){} указываем кодировку
- Console.OutputEncoding = Encoding.UTF8;
и пишем структуру нашего граббера html
- using (var browser = new IE("http://www.yvision.kz"))
- {
- Settings.WaitForCompleteTimeOut = 999999999; /*увеличиваем тайм-аут на всякий случай*/
- var doc = new HtmlDocument(); /* инсталляция объекта парсера HTML Agility Pack*/
- doc.LoadHtml(browser.Body.OuterHtml); /*помещаем в парсер полученный html с страницы yvison.kz*/
- }
- Console.Write("Done!"); /*текст после завершения скрипта*/
- Console.ReadKey(); /*ожидание нажатия клавиши*/
таким образом мы имеем следующий код:
- скрипт открывает браузер IE
- переходит по адресу http://www.yvision.kz
- забирает HTML разметку
- отдает парсеру
далее нам нужно распарсить информацию с html и например отобразим их в консоле, приступим.
Например получим 4 последних сообщения с главной страницы:
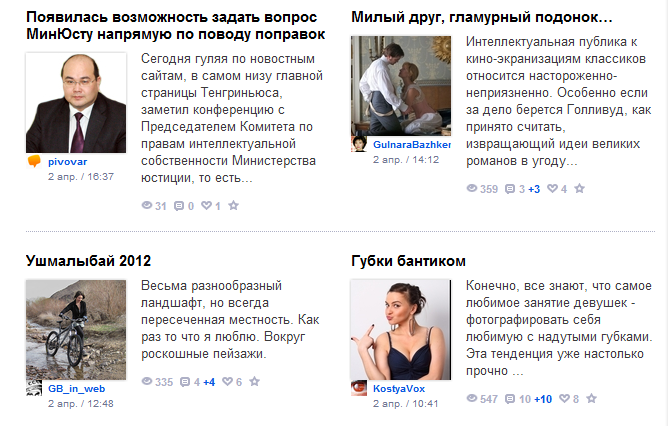
Смотрим структуру HTML, и видим что эти блоки лежат в div с классом .mainContent.main_page
каждым отдельный блок имеет класс .half-l
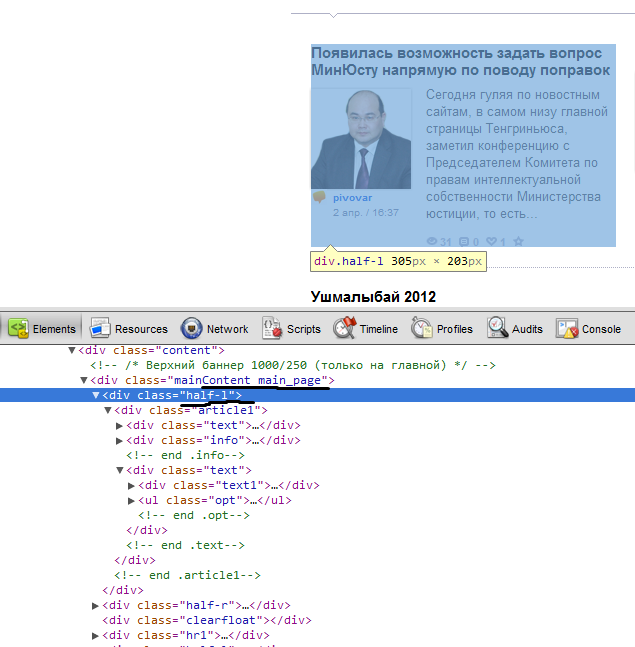
отсюда следует что нам нужно из полученного HTML страницы, взять контент который находится в диве с классом .mainContent.main_page
и выбрать из него все дивы с классом .half-l Приступим.
- namespace ConsoleApplication1
- {
- using HtmlAgilityPack;
- using System;
- using WatiN.Core;
- class Program
- {
- [STAThread]
- static void Main()
- {
- Console.OutputEncoding = Encoding.UTF8;
- using (var browser = new FireFox("http://www.yvision.kz"))
- {
- Settings.WaitForCompleteTimeOut = 999999999;
- var doc = new HtmlDocument();
- doc.LoadHtml(browser.Body.OuterHtml);
- var dataBlock = doc.DocumentNode.SelectSingleNode("//div[@class=\"mainContent main_page\"]"); /*получаем в переменную все блоки из дива .mainContent.mainpage*/
- foreach (var item in dataBlock.SelectNodes("//div[@class=\"half-l\"]")) /*в цикле проходим по каждому диву с классом .half-l*/
- {
- Console.Write( item.InnerHtml + "\n"); /*показываем в консоли содержимое дива*/
- }
- }
- Console.Write("Done!");
- Console.ReadKey();
- }
- }
- }
Теперь можете запустить приложение и проверить - F5 в Visual Studio
должно выглядеть примерно так
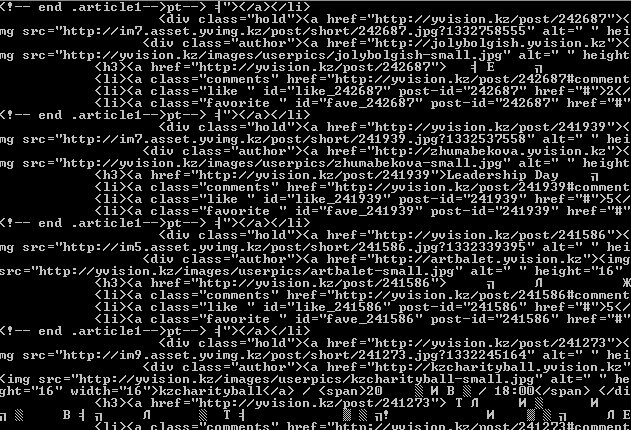
блоки мы вывели, но нужно отсеять не нужную информацию, давайте из каждого блока возьмем только ссылку на статью и адрес картинки
видим что путь до ссылки "div.text > h3 > a" и путь до картинки у нас div.info> div.photo> div.hold> a > img

значит код выборки будет следующий
- Console.Write("Link item: " + item.SelectSingleNode("//div[@class=\"info\"]/div[@class=\"photo\"]/div[@class=\"hold\"]/a").Attributes["href"].Value + "\n"); /*выбираем ссылку*/
- Console.Write("Images patch: " + item.SelectSingleNode("//div[@class=\"info\"]/div[@class=\"photo\"]/div[@class=\"hold\"]/a/img").Attributes["src"].Value + "\n"); /*выбираем адрес картинки*/
Весь листинг выглядит так
- namespace ConsoleApplication1
- {
- using HtmlAgilityPack;
- using System;
- using WatiN.Core;
- class Program
- {
- [STAThread]
- static void Main()
- {
- Console.OutputEncoding = Encoding.UTF8;
- using (var browser = new FireFox("http://www.yvision.kz"))
- {
- Settings.WaitForCompleteTimeOut = 999999999;
- var doc = new HtmlDocument();
- doc.LoadHtml(browser.Body.OuterHtml);
- var dataBlock = doc.DocumentNode.SelectSingleNode("//div[@class=\"mainContent main_page\"]");
- int cntItem = 0; /*добавим счетчик, мы ведь будем выводить только 4 записи*/
- foreach (var item in dataBlock.SelectNodes("//div[@class=\"half-l\"]"))
- {
- cntItem++; /*увеличиваем счетчик на один*/
- Console.Write("Link item: " + item.SelectSingleNode("//div[@class=\"info\"]/div[@class=\"photo\"]/div[@class=\"hold\"]/a").Attributes["href"].Value + "\n");
- Console.Write("Images patch: " + item.SelectSingleNode("//div[@class=\"info\"]/div[@class=\"photo\"]/div[@class=\"hold\"]/a/img").Attributes["src"].Value + "\n");
- Console.Write("\n*****yvision.kz*******\n\n"); /*визуально разграничим результаты текстом*/
- if(cntItem == 4) {break;} /*если выбрали 4 записи то остановить цикл*/
- }
- }
- Console.Write("Done!");
- Console.ReadKey();
- }
- }
- }
Запустим программу и увидим
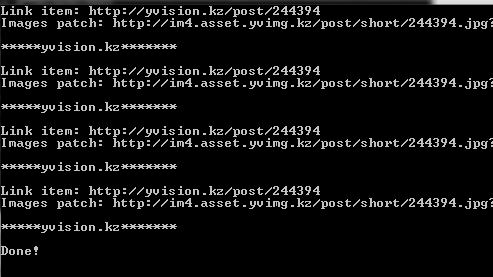
Работает! Далее с этой информацией можете делать что душе угодно, например: положить в базу данных чтоб отображать на сайте.
P.S если парсить много контента за один раз то в браузере лучше отключить отображение картинок, тогда парсинг займет меньше времени.
Успехов!