

В этой короткой записке написано как сделать софт рейд на примере CentOS 6.4
Для организации отказоустойчивости дисковой подсистемы на серверах и на обычных пользовательских компьютерах создают рейд массивы, которые позволяют не потерять важных данных в случаи поломки жесткого диска. Все строится на том, что в такой системе используется два жестких диска c одинаковым объемом. Данные поступающие на запись, например, допустим один файл, записывается на первый и второй диск. Если из строя выйдет один жесткий диск, второй продолжит работать с тем же файлом не заметно для пользователя. Тем самым позволяя добиться отказоустойчивости дисковой подсистемы, сгоревший диск на горячую заменяется на новый, и данные со второго диска (в ручную или автоматически) начинают записываться на уже новый жесткий диск.
Все операции проводимые с жесткими дисками очень опасны для данных, вы можете потерять всю информацию. Если конечно таковая имеется. Любые манипуляции надо производить только тогда, когда есть резервная копия критически важных данных.
Рассмотрим два случая создания программного рейд массива:
1. Системный диск c уже работающей CentOS + Рейд массив из двух одинаковых жестких диска.

2. Чистая установка CentOS на два диска присутствующих в системе.

Эти два случая создания рейд массива очень распространены. Например в первом случае мы можем держать один системный загрузочный диск, а на двух жестких дисках в массиве располагать виртуальные машины. Львиная доля нагрузки при этом будет обработана рейд массивом. Потому что дисковые операции в основном придутся на массив, так как виртуальные машины часто будут писать и считывать на диск.
Второй случай, тоже очень таки используемый. Например у нас есть почтовый сервер и мы хотим повысить дисковую отказоустойчивость. Если сгорит один жесткий диск в таком сервере, другой диск продолжить работать.
Конечно в обоих случаях нужно в обязательном порядке следить за здоровьем массива, для этого используют утилиту считывающею данные SMART. Если жесткий диск сломается, утилита может оперативно вас про информировать, чтобы вы, в дальнейшем заменили один из жестких дисков рейда.
В конце записки есть небольшая инструкция по замене сбойного диска на новый рабочий.
Первый случай: Системный диск + Рейд массив из двух одинаковых жестких диска.
Допустим у нас имеется сервер с одним жестким диском, этот диск системный. Мы добавили к нему еще два жестких диска объемом 35 Гбайт для организации программного рейда.
Краткое содержание:
1. Определяем какие жесткие диски будут в рейде
2. Создаем рейд массив из двух HDD
3. Записываем файловую систему в рейд
4. Создаем конфиг файл утилиты mdadm
5. Монтируем рейд в системе
6. Автомонтирование рейд массива при загрузке системы
1. Определяем какие жесткие диски будут в рейде
Чтобы определить какие жесткие диски есть в системе, введем комманду:
# fdisk -l | grep "Disk /dev/sd"
Disk /dev/sda: 18589 MB, 8589934592 bytes
Disk /dev/sdb: 1008589 MB, 8589934592 bytes
Disk /dev/sdc: 1008589 MB, 8589934592 bytes
Здесь мы видим что у нас в компьютере имеется три физических жестких диска, это:
1. sda
2. sdb
3. sdc
Первый жесткий диск sda является системным, его размер 18 Гбайт, а два добавленных пустые. Из них будем делать рейд.
2. Создаем рейд массив из двух HDD
Установим mdadm:
# yum install mdadm -y
Для организации рейд массива зеркального типа (уровень 1).
Вводим следующею команду для создания рейд массива:
# mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb /dev/sdc
Continue creating array? y
Здесь мы не указываем определенные разделы, так как у нас их нет. Поэтому мы сразу написали имена дисков участвующих в массиве sdb и sdc. Разделы пишутся так sdb1 или sdb2.
Рассмотрим данную команду по ближе:
-- level - задает тип рейд массива, это может быть 0, 1, 5, 6.
--raid-devices - задает количество дисков участвующих в организации рейда
/dev/sdb - первый жесткий диск
/dev/sdc - второй жесткий диск
/dev/md0 - собственно, имя создаваемого массива
Проверяем, создался ли массив:
# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc[1] sdb[0]
8387572 blocks super 1.2 [2/2] [UU]
3. Записываем файловую систему в рейд
Разметим пространство создав файловую систему на нашем рейде, в качестве ФС (файловая система) берем ext4:
# mkfs.ext4 /dev/md0
4. Создаем конфиг файл утилиты mdadm
Теперь, создадим конфиг файл для утилиты mdadm:
# mdadm --detail --scan --verbose > /etc/mdadm.conf
Осталось не много, при монтируем наш рейд в системе, чтобы в него могли писать программы.
5. Монтируем рейд в системе.
Создадим точку монтирования, каталог /raid:
# mkdir /raid
При монтируем рейд в каталог /raid:
# mount /dev/md0 /raid
Второй способ монтирования, он более безопасный:
# vi /etc/rc.d/rc.local
/bin/mount -t ext4 /dev/md0 /raid
6. Автомонтирование рейд массива при загрузке системы
Чтобы ваш рейд всегда автоматически монтировался при загрузке ОС, добавьте строчку в файл /etc/fstab:
/dev/md0 /raid ext4 defaults 1 2
Заключение:
Итого мы имеем программный рейд массив уровня 1 (зеркалирование) на двух дисках, помимо отдельного системного диска. Это будет полезно при работе гипервизора или когда нужно хранить отдельно важные данные.
Второй случай: Рейд массив из двух дисков имеющихся в системе
Этот случай самый распространенный, именно его используют многие админы.
Допустим у нас новенький сервер, в нем установлено два жестких диска объемом 35 Гб.
Рейд массив в этом случае будет создаваться во время установки операционной системы.
Кратко надо будет сделать следующее:
1. Во время установки операционной системы создать одинаковые разделы на двух жестких дисках:
- swap - раздел подкачки, размер 1 Гб
- RAID partition - раздел RAID, выделить под него все оставшееся место за вычетом 1Гб
2. Объеденить оба жестких в рейд массив
3. Установить систему на рейд массив
4. Установить загрузчик на диск sdb
5. Настроить конфигурационный файл загрузчика, чтобы загрузка шла в случае неудачи с диска который еще работает.
Вроде все ясно.
Приступим....
Покажу как это делается в картинках. Вставляем DVD диск с CentOS в компьютер и перезагружаемся.
Нажимаем первый пункт, установка или обновление.
Нажимаем кнопку "SKIP"

Нажимаем NEXT
Нажимаем NEXT
Нажимаем NEXT
Нажимаем NEXT
Нажимаем NEXT
Нажимаем NEXT

Вводим пароль суперадминистратора
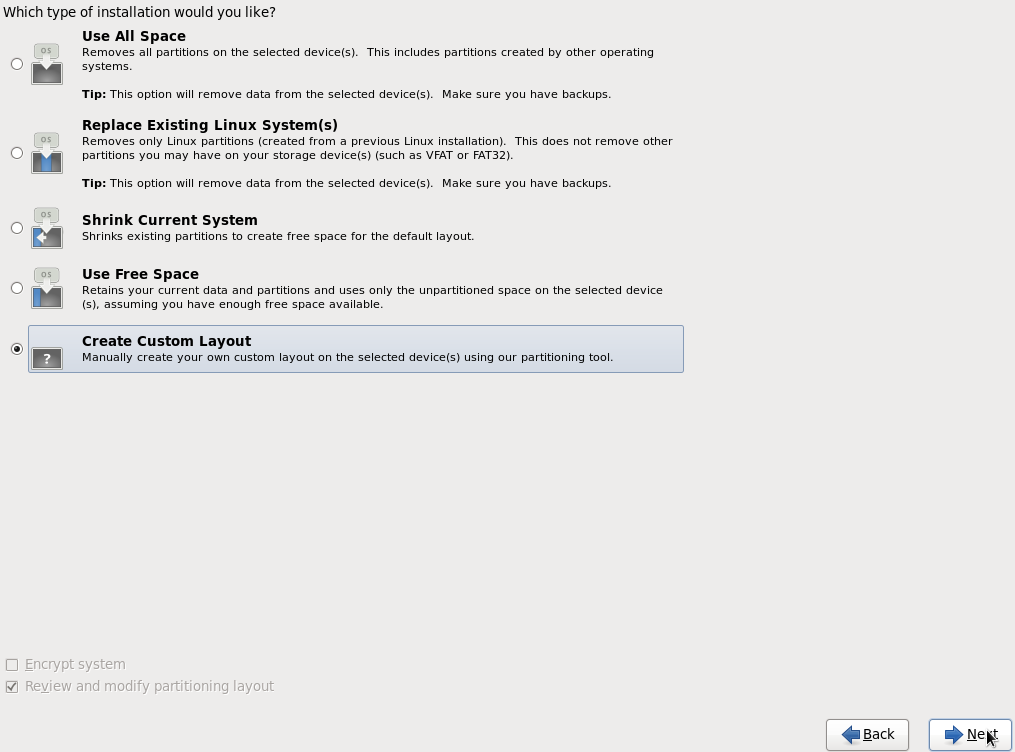
Выбираем "Create Custom Layout"
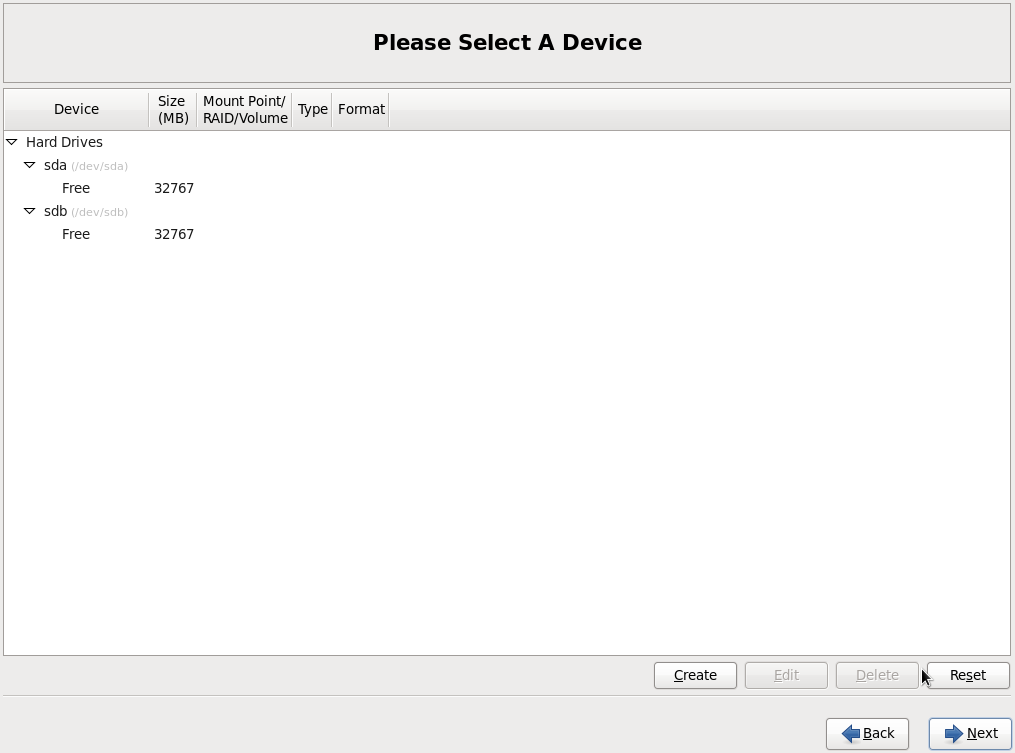
Видим два жестких диска sda и sdb, нажимаем CREATE
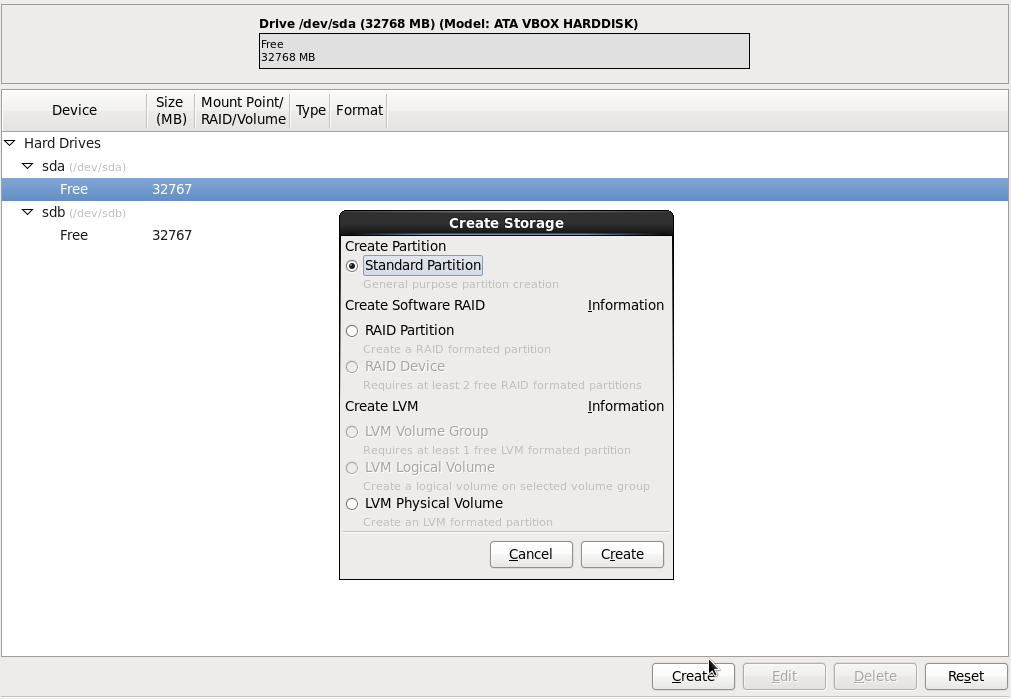
Выбираем Standart Partition и жмем Create.
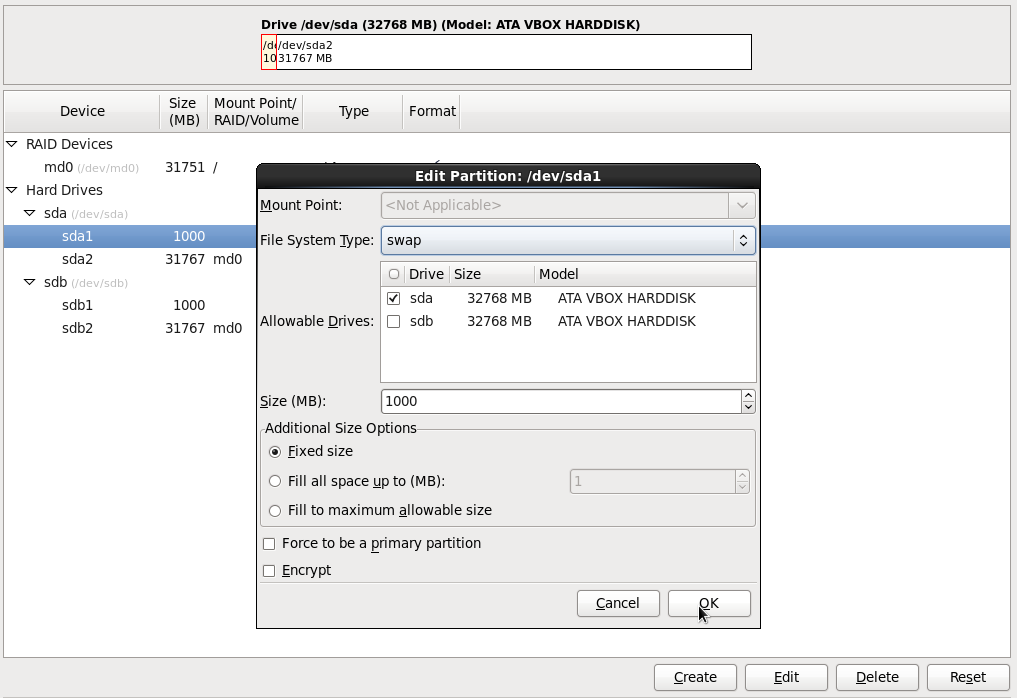
Ставим галку напротив диска sda как на картинке.
Выбираем File System Type = swap и указываем размер 1000 MB
Заполняем и нажимаем кнопку OK, после чего создаться раздел SWAP объемом 1000 MB
Теперь создадим корневой раздел /.
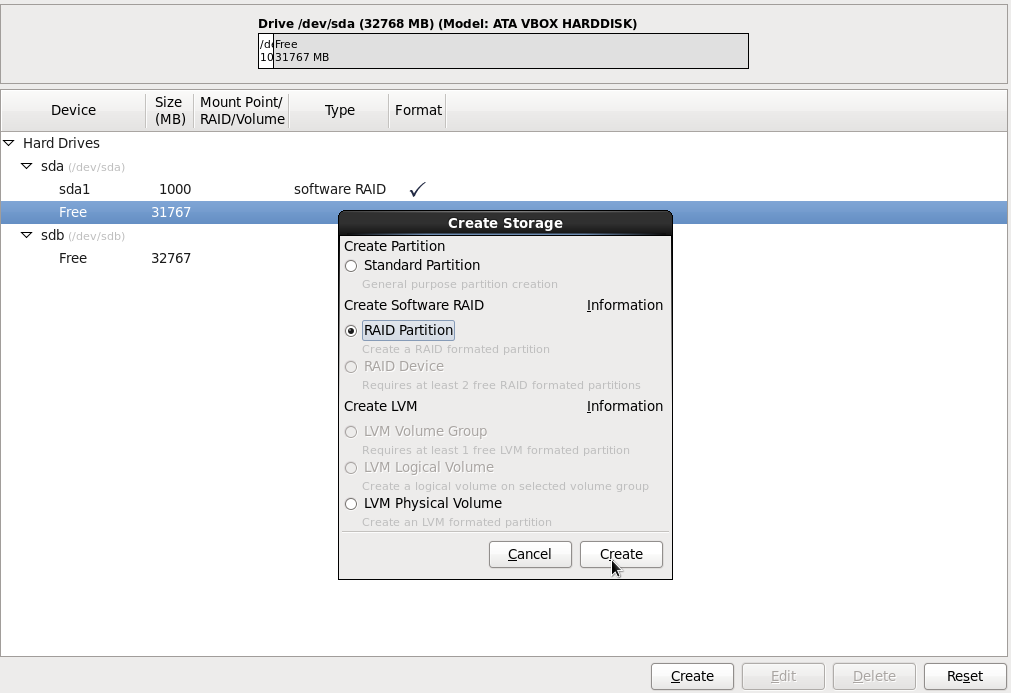
Нажимаем опять кнопку Create. Выбираем RAID Partition как на картинке.
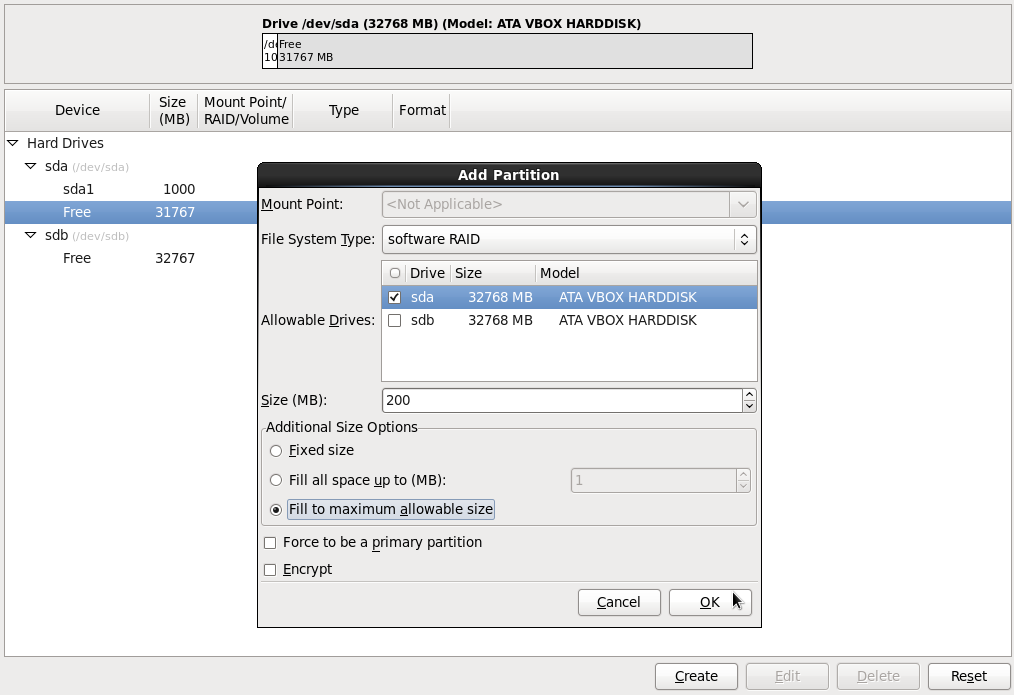
Ставим галочку на sda диске, выбираем File System type = software RAID.
А также ставим выбираем Fill to maximim alowable size и нажимаем кнопку OK.
Все, мы создали два раздела на первом жестком диске sda. Аналогичную операцию требуется проделать со вторым жестким диском sdb.
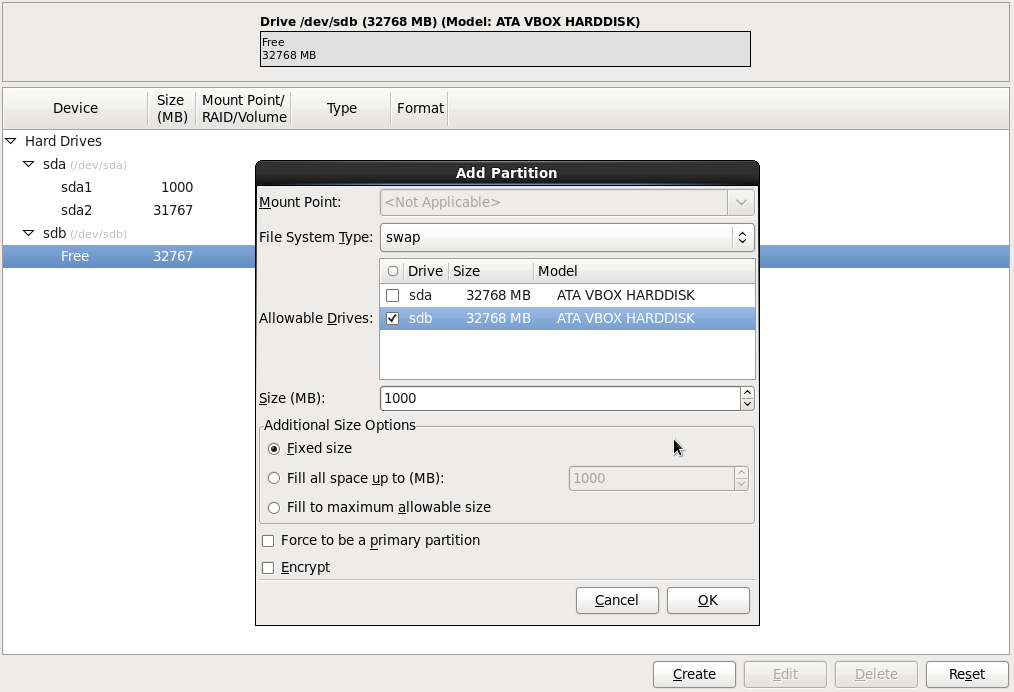
Нажимаем кнопку Create. Выбираем второй жесткий диск sdb (галка). Создаем на нем раздел Swap, объемом в 1000 МБ.
Галочка Fixed size.
Size - 1000
Нажать кнопку OK.
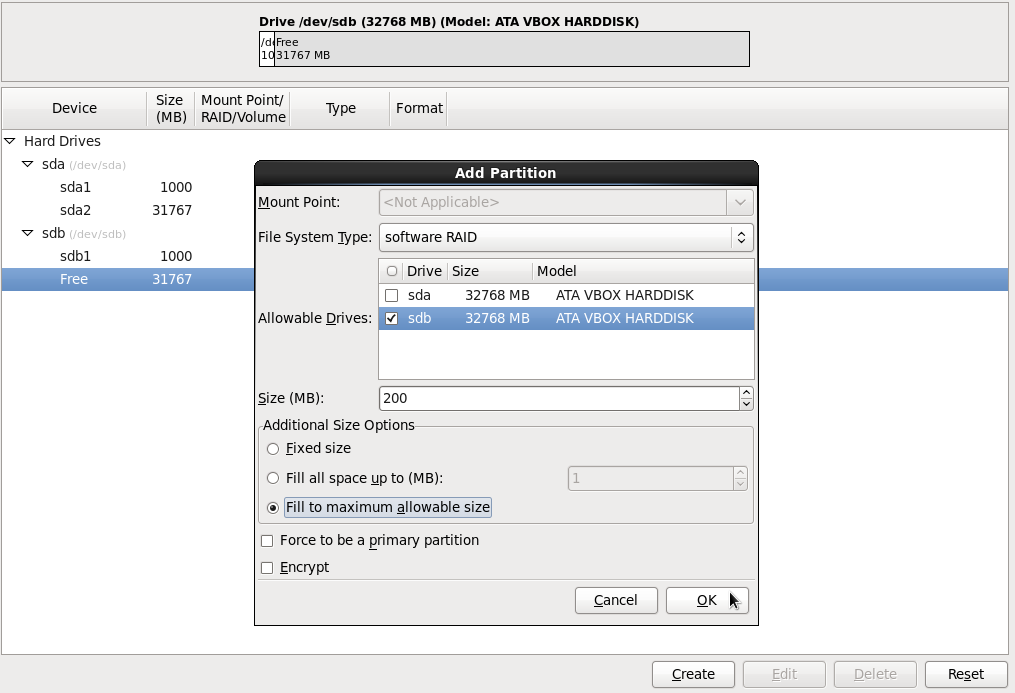
Нажимаем кнопку Create, выбираем File System Type- Software RAID
Галка - Fill to maximum allowable size
Кнопка - OK
Теперь у нас созданы одинаковые разделы двух жестких дисках.
Осталось объеденить эти два диска в RAID массив.
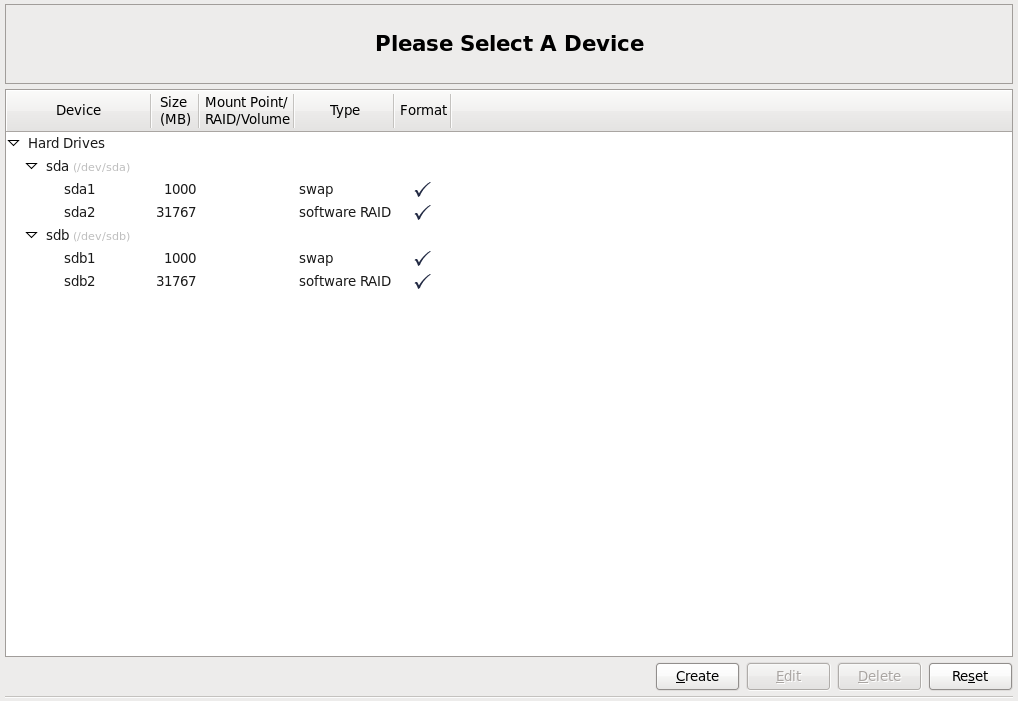
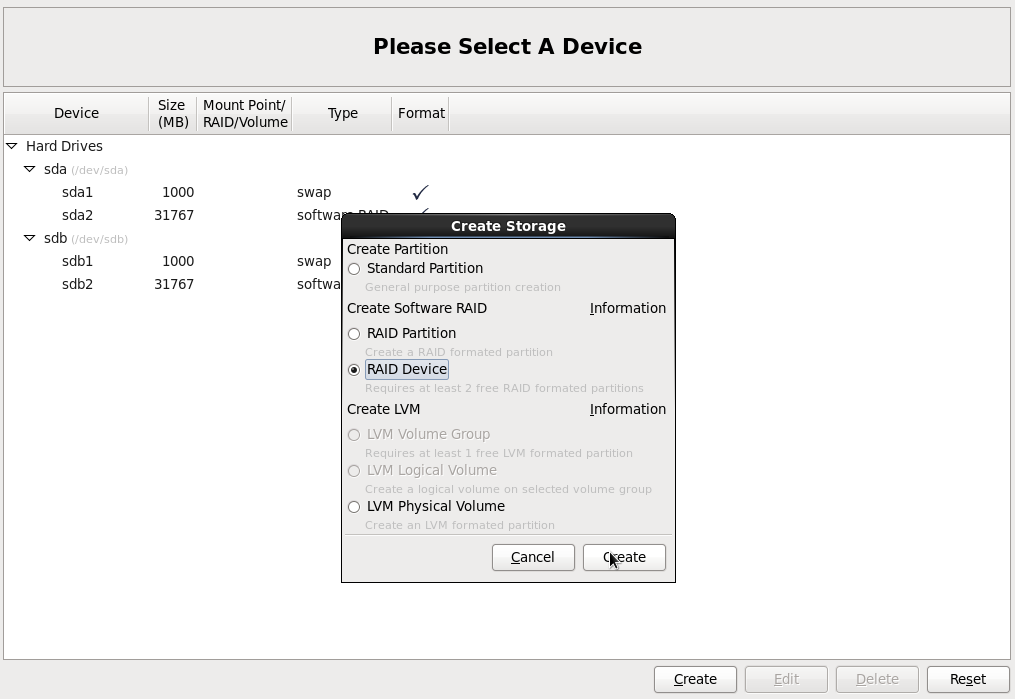
Нажимаем как обычно по кнопке Create, выбираем RAID Device.
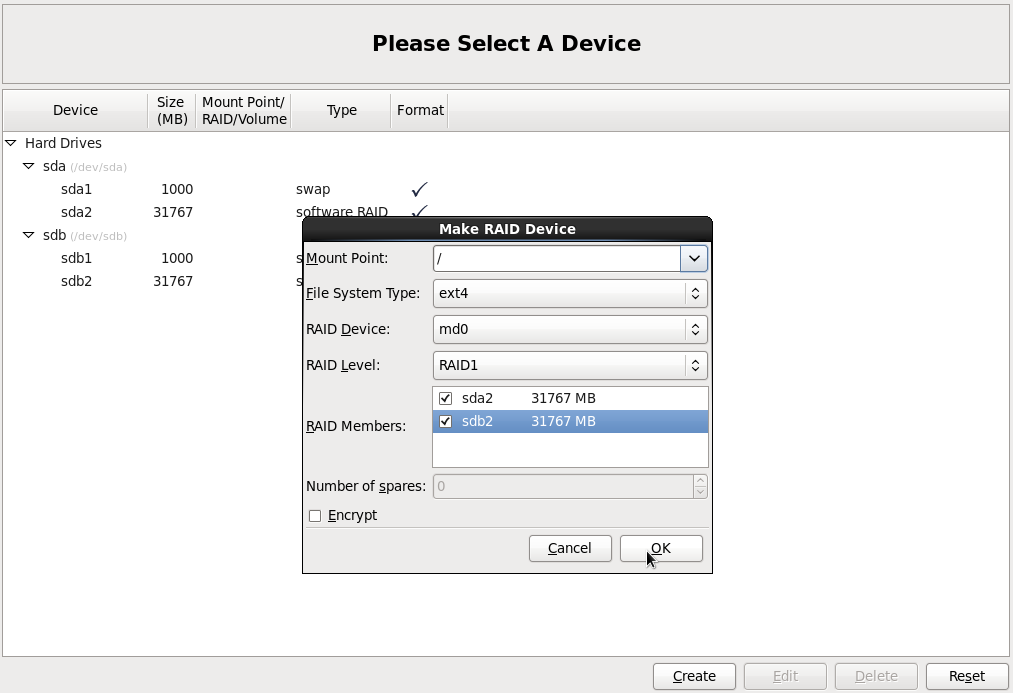
Mount Point: /
File System Type: Ext4
RAID Device: md0
RAID Level: RAID1
Галочки напротив sda и sdb дисков.
Кнопка OK.
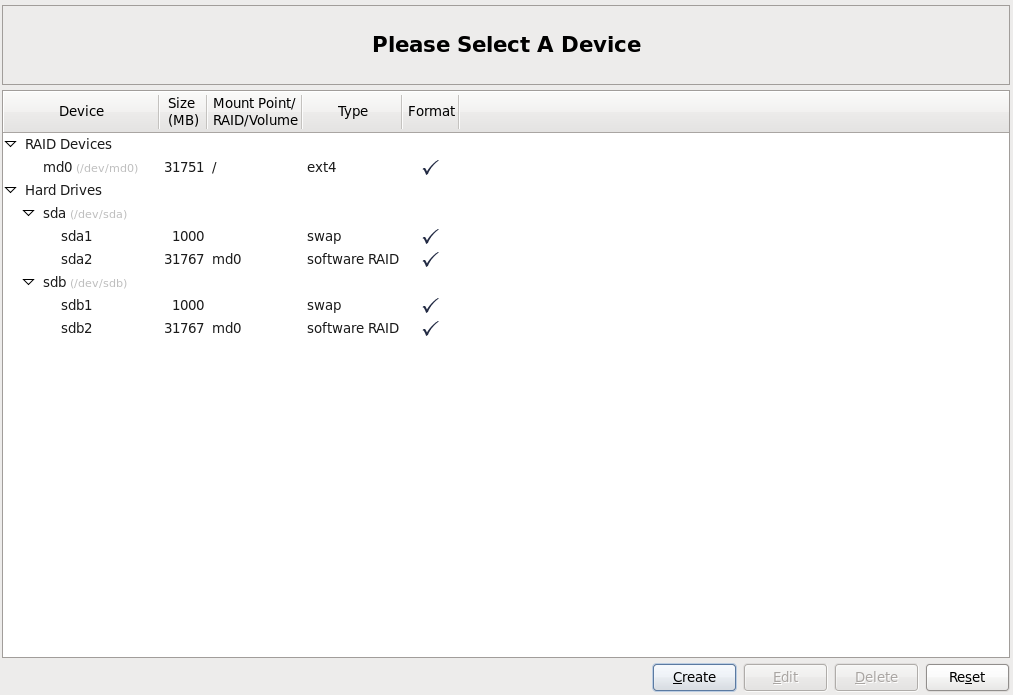
Все рейд массив создан. Осталось установить на него операционную систему.
Нажимаем по кнопке Next.
Нажимаем Write changes to disk.
Нажимаем Next, загрузчик Grub будет установлен на диск sda. После установки ОС, мы скопируем его на второй диск sdb,
чтобы система грузилась с любого диска в случае краха одного из них.
Минимальная инсталяция. Нажимаем Next
Процесс установки системы.
Установка завершена, нажмите Reboot для перезагрузки.
Вводим логин root
Пароль свой.
Проверим состояние массива:
# cat /proc/mdstat
Копируем загрузчик Grub на второй жесткий диск sdb.
Вводим в терминале:
# grub
grub> find /boot/grub/stage1
hd (0,1)
hd (1,1)
grub> root (hd0,1)
grub> setup (hd0)
grub> root (hd1,1)
grub> setup (hd1)
grub> quit
Этими командами мы скопировали загрузчик на второй жесткий диск sdb.
Теперь подправим конфигурационный файл grub.conf
# vi /boot/grub/grub.conf
Добавляем в этот файл строчку:
fallback=1
Этот параметр позволит загрузчику в случае неудачи загрузки с диска sda, загрузится с диска sdb.
А также надо удалить или закоментить строку:
splashimage=(hd0,1)/boot/grub/splash.xpm.gz
Но осталось еще добавить следующие строчки, чтобы Grub мог загрузится со второго жесткого диска:
title CentOS (2.6.32-358.el6.i686)
root (hd1,1)
kernel /boot/vmlinuz-2.6.32-358.el6.i686 ro root=UUID=fc8b1c7e-2529-4c2a-accf-3b27004968a6 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_MD_UUID=0dbaca2b:ef34020c:3a8414fa:f4311c8c SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet
initrd /boot/initramfs-2.6.32-358.el6.i686.img
Вот полный файл grub.conf
# grub.conf generated by anaconda
#
# Note that you do not have to rerun grub after making changes to this file
# NOTICE: You do not have a /boot partition. This means that
# all kernel and initrd paths are relative to /, eg.
# root (hd0,1)
# kernel /boot/vmlinuz-version ro root=/dev/md0
# initrd /boot/initrd-[generic-]version.img
#boot=/dev/sda
default=0
timeout=5
fallback=1
#splashimage=(hd0,1)/boot/grub/splash.xpm.gz
hiddenmenu
title CentOS (2.6.32-358.el6.i686)
root (hd0,1)
kernel /boot/vmlinuz-2.6.32-358.el6.i686 ro root=UUID=fc8b1c7e-2529-4c2a-accf-3b27004968a6 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_MD_UUID=0dbaca2b:ef34020c:3a8414fa:f4311c8c SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet
initrd /boot/initramfs-2.6.32-358.el6.i686.img
title CentOS (2.6.32-358.el6.i686)
root (hd1,1)
kernel /boot/vmlinuz-2.6.32-358.el6.i686 ro root=UUID=fc8b1c7e-2529-4c2a-accf-3b27004968a6 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_MD_UUID=0dbaca2b:ef34020c:3a8414fa:f4311c8c SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet
initrd /boot/initramfs-2.6.32-358.el6.i686.img
Обязательно закоментируйте строчку:
splashimage=(hd0,1)/boot/grub/splash.xpm.gz
В противном случае будете видеть следующею ошибку если один из дисков умрет:
failed to read image
Все, теперь все должно работать! Проверьте чтобы в настройках Grub у вас были одинаковые настройки для двух дисков, в противном случае будут проблемы с загрузкой.
Чтобы массив быстрее перестраивался, можно внести специальную настройку:
# echo 50000 >/proc/sys/dev/raid/speed_limit_min
Обязательно, после всех проделанных операций, проверяйте как ведет себя массив без одного жесткого диска. Грузится ли система с одним диском.
Замена диска в массиве
Бывает так, что со временем диск в массиве умирает. Он может просто не определятся в BIOS (CentOS) или может чудить из за механических поломок или плохой поверхности.
Процедура замены в случае сгоревшего диска следующая:
1. Выключаете сервер
2. Вынимаете сгоревший диск и устанавливаете новый
3. Создаете разделы на новом диске как на выжившем работающем носителе.
4. Добавляете новый диск в массив.
5. Копируете загрузчик grub
Давайте рассмотрим последовательность замены диска если команда рапортует нам о нехватке диска в массиве - [U_]
# cat /proc/mdstat
cat /proc/mdstatPersonalities : [raid1]md0 : active raid1 sda2[0]7875520 blocks super 1.0 [2/1] [U_]bitmap: 1/1 pages [4KB], 65536KB chunkunused devices: <none>
Как видим одного диска - нет!
Теперь сама процедура:
1. Выключаете сервер
# shutdown -h now
2. Вынимаете сгоревший диск и устанавливаете новый
Открутите винты и отсоедините шлейфы - уберите сгоревший диск.
За место него установите заведомо исправный диск.
3. Создаете разделы на новом диске как на выжившем работающем носителе.
Включите сервер и введите команду:
# sfdisk -d /dev/sda | sfdisk /dev/sdb --force
Этой командой мы копируем разделы с диска sda на диск sdb. Диск sda - это выживший, а диск sdb - это новый диск напарник.
Чтобы система увидела новые разделы диска sdb введите:
# sfdisk -R /dev/sdb
4. Добавляете новый диск в массив.
Далее, добавляйте новый диск в массив:
# mdadm /dev/md0 --add /dev/sdb2
5. Копируете загрузчик grub
Вводим в терминале:
# grub
grub> find /boot/grub/stage1
hd (0,1)
hd (1,1)
grub> root (hd0,1)
grub> setup (hd0)
grub> root (hd1,1)
grub> setup (hd1)
grub> quit
Процедура замены в случае если S.M.A.R.T. выдает неутишительный отчет с диагнозом - диск скоро умрет:
1. Убираете диск из массива
2. Выключаете сервер
2. Вынимаете сгоревший диск и устанавливаете новый
3. Создаете разделы на новом диске как на выжившем работающем носителе.
4. Добавляете новый диск в массив.
5. Копируете загрузчик grub
Здесь все тоже самое что и в первом случае, за исключением одного но - точнее первого пункта:
Чтобы убрать диск из массива введите команду:
# mdadm --manage /dev/md0 --fail /dev/sdb
Здесь мы указали что диск sdb сбойный, и что с ним работать уже нельзя.
Далее можно удалить его из массива:
# mdadm /dev/md0 -r /dev/sdb
Процедура добавления нового диска в массив идет уже по описанной процедуре которую я описал выше.
Краткий FAQ:
1. Массив создался под именем md0 с двумя разделами sda2 и sdb2, после отключения одного из дисков и дальнейшего включения массивов стало два md0 и md127. В первом md0 диск раздел sda2, а во втором md127 раздел диск sdb2.
Решение:
Отключаем массив md127:
# mdadm -S /dev/md127
Добавляем диск sdb2 в массив md0:
# mdadm /dev/md0 --add /dev/sdb2
Проверяем состояние массива:
# cat /proc/mdstat
Должна быть синхронизация...
Или, если первый способ не прошел, значить делаем так:
Создаем новый конфиг mdadm:
mdadm --detail --scan --verbose > /etc/mdadm.conf
Такое может быть если нету конфигурационного файла /etc/mdadm.conf
Ну и потом как обычно, делаем настройку для автомонтирования при загрузки системы:
Открываем файл /etc/fstab
и добавляем строчку для монтирования:
/dev/md0 /raid ext4 defaults 1 2
2. Как скопировать загрузчик Grub с одного диска на другой в массиве. Чтобы система грузилась при неудачной загрузки с одного из дисков.
Решение:
Находим разделы дисков:
# grub
> find /boot/grub/stage1
hd (0,1)
hd (1,1)
Копируем загрузчик:
> root (hd0,1)
> setup (hd0)
> root (hd1,1)
> setup (hd1)
> quit
3. Не правильно при монтировал массив в /etc/fstab, теперь файловая система упала в режим Read Only, что делать?
Появляются ошибки при редактировании файл /etc/fstab вроде этих:
W10: Warning: Changing a readonly file
E45: 'readonly' option is set (add !to override)
Решение:
Главное не паниковать, если не правильно при монтирован массив, то файловая система просто перейдет в режим Read Only.
Нам необходимо смонтировать файловую систему в режиме записи, для этого вводим следующею команду:
# mount -o remount,rw /
И далее исправить /etc/fstab так чтобы массив нормально функционировал.
4. Как сделать не большой тюнинг массива уровня 5?
Решение:
Добавляем в /etc/rc.d/rc.local строчку:
echo 8192 > /sys/block/md0/md/stripe_cache_size